記一個小工具:實現聊天記錄

最近做了一個截圖拼接的小玩具,實現聊天記錄/朋友圈截圖的自動拼接,感覺還是比較有趣,所以記上一筆和大家分享。
緣起
經常有這樣的場景:需要將微信的聊天記錄/網頁轉發給其他人,內容很長,所以不得不一段一段地截圖發送,麻煩又常有亂序送達的情況發生。於是在 App Store 上找了款自動拼接截圖的 App (截圖拼接),很是好用,卻有一天只能保存一次的限制。於是自己寫了一個玩,花了一天寫算法驗證可行性,又花了一天將界面和流程整理好,比那個 App 快上數倍,很是滿足。不過想想 2 天的工資怎麼也超過那個 App 的價格了...
實現
要實現兩張截圖的自動拼接,首要問題是找到它們的重復內容。簡單粗暴的想法就是對兩張圖片進行逐行掃描並比較每一行的像素點以確定當前行是否匹配,然後找出連續匹配的最大行數即可。但簡單推演一下,iPhone 6 的截圖分辨率為750 * 1334,進行上述操作至少需要上萬億的匹配,計算量和效率可想而知。所以需要些小技巧減少計算量。
提取圖片指紋
對於判斷圖片任意兩行是否一致來說,行內每個像素點信息其實並沒有什麼意義,我們更關注的是整行的數據信息。一張寬為 750 的圖片,每行都有 3KB 字節數據,逐一比對顯然數據量過大。所以第一步就是將行數據進行"壓縮",用比較高大上的詞來說就是“提取圖片指紋”。最簡單的方式是計算這一片數據的 MD5。這種方式既可以將 3KB 的數據壓縮至幾十個字節,又可以保證唯一性。
然而這種強哈希的做法有兩個弊端:
計算量大
結果表現是形式為字符串,不利於下一步比較
所以最終選擇使用 CRC 這種弱哈希的方式來作為提取圖片指紋的方式。一方面計算快,另一方面得到的結果為數字,有利於加快後續的匹配速度。而弱哈希帶來的沖突問題則可以忽略不計:最終匹配時需要找出連續相同的行數據,使得偶現的沖突對整個匹配結果正確性影響微乎其微。
匹配圖片指紋
使用 CRC 提取圖片指紋後,能方便地將一張 iPhone 6的截圖轉換為 1334 個 unsigned long 的數字集合,整個問題就簡化為尋找兩個串內的公共子串。簡單粗暴的方法是直接遍歷每一行,在某兩行匹配的情況下繼續比較下兩行,直到找到最大匹配項集合。最差情況下時間復雜度為 O(n^4),這是理論上不可接受的時間復雜度。但是在實際測試中,由於圖片指紋的特殊性,使得匹配速度並沒有想象中的那麼差,兩張 iPhone 6的圖片指紋匹配大約需要 100 到 500 ms之間。
一種改進的方式是使用動態規劃,用空間換時間。假設圖 1 高為 m, 圖 2 高 為 n,圖 1 的第 i 行與圖 2 的 j 行內容一致,用 c[i,j] 表示以 i,j 行作為結尾的最長公共子串長度,則有:c[i,j] = c[i-1,j-1] + 1。基於這個原理,我們建立一個 m * n 的二維數組,只需要一次遍歷就可以找出最大子串,復雜度為O(n^2)。使用這種方法,兩張 iPhone 6 圖片指紋匹配只需要 10 到 50 ms。
多圖拼接
對於兩張圖而言,一旦找到最大相同行,只需要將兩張圖分別切割成 上圖上部分,共同部分和下圖下部分進行拼接即可。但是如果有多張圖,情形則復雜得多,相鄰兩對圖的相同部分可能有如下三種情況:包含,相交,不相交。這使得預先計算多圖拼接後的圖片大小和各個圖的裁剪區域變得極其復雜和困難。(如果有什麼好的方法可以直接計算出對應關系,請告訴我)
所以在我的實現裡使用了遞歸的方式來實現。這個地方有個小 trick,當前面兩張圖片合並為一張新圖後,由於新圖大小發生變化,導致後續兩張圖匹配行數也發生偏移,需要重新調整。但是考慮到所有的圖片都是從上往下進行拼接,所以在匹配時直接使用距底部距離作為偏移值,這樣就避免了合並後的圖片需要重新計算匹配行偏移的情況。
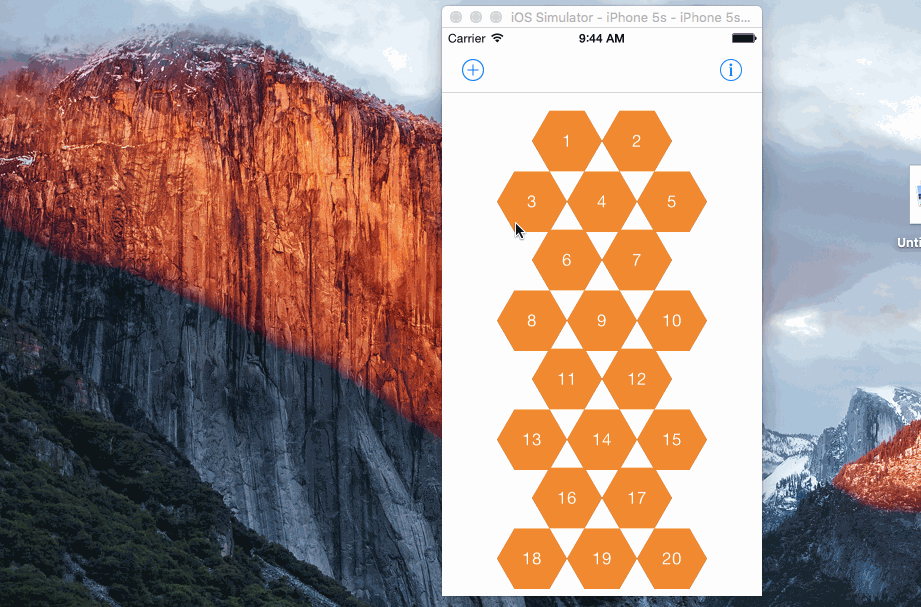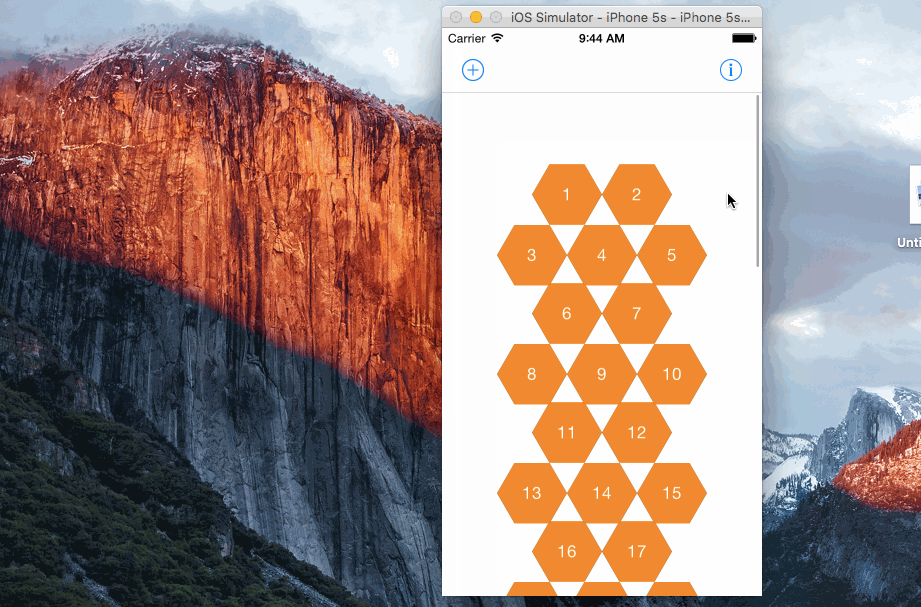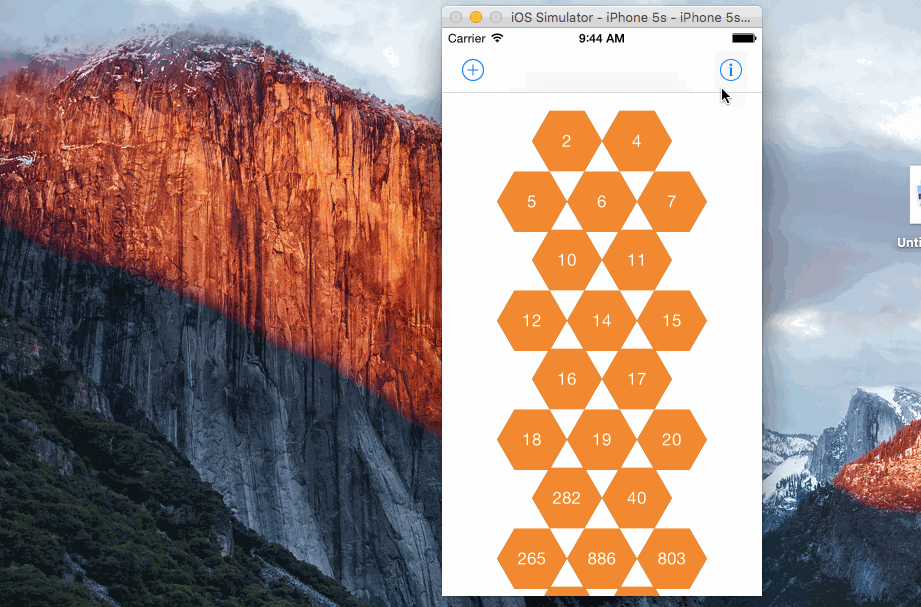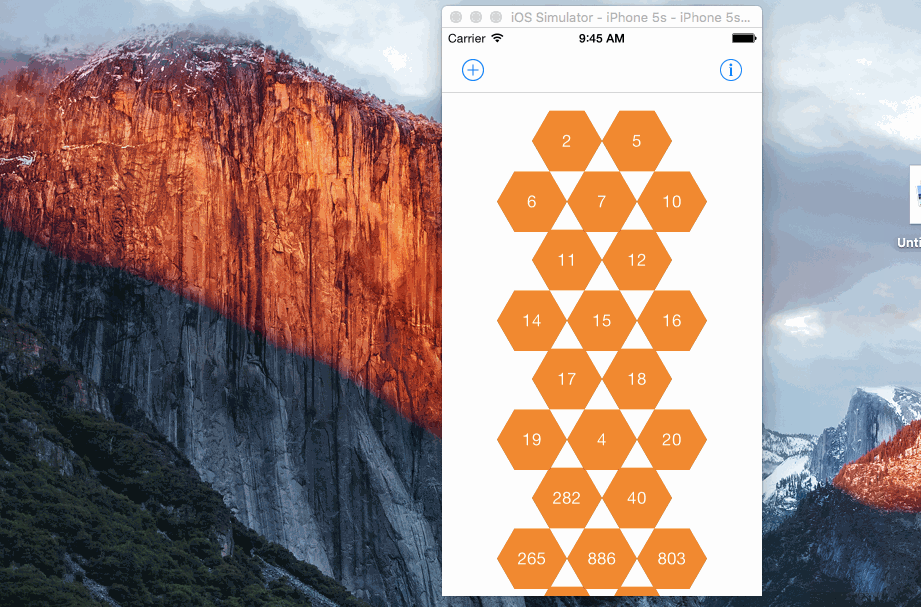
效果
效果還是不錯的,天衣無縫:


可改進的點
動態規劃在超長圖合並時申請的內存數可能會超過幾十兆,但實際進行比較時其實只需要記錄上一行數據和最大值即可,所以並不需要申請 m * n 的二維數組,只需要 2 * n 大小的二維數組即可。(=。= 懶得改了)
對於非靜態的內容匹配會失敗,如聊天內容中帶有會動的表情。能夠想到的方法是使用類似 SIFT 或者 SURF 之類的算法計算出相應的 Interesting Point 並配合前面的算法進行匹配,但這種方法難度太高,可行性也不高。
代碼
具體的實現細節可以參考M80ImageMerger


- 蘋果iPhone7字母數字密碼怎麼設置?
- iOS9.1怎麼越獄 盤古iOS9.1完美越獄教程
- 簡單技巧:如何讓iPhone5s存儲25個指紋
- iPhone5黑白屏幕怎麼設置?
- 自定義導航欄按鈕
- iPhone6機身存儲16G夠不夠? iPhone6/ipad的16G夠不夠?[多圖]
- 蘋果暫停iPhone5s及更早設備的iOS9.3正式版推送
- 買一部ipad還是ipone好呢?我就是有了iPhone4了。打算買個4S或者是the new ipad。ipad2也可以。我是學生。
- iOS瘋狂詳解之UITableView的全選和多選功能 – iPhone手機開發技術文章 – 紅黑聯盟
- iphone5電池容量越用越少的原因
- iOS開源一個簡略的訂餐app UI框架
- 在uiview 的tableView中點擊cell進入跳轉到另外一個界面的完成辦法
- iOS 和 Android 哪一個更利於賺錢?
- 一個辦法弄定iOS下拉縮小及上推減少
- iOS開辟中完成一個簡略的圖片閱讀器的實例講授
- iOS開辟中應用Picker View完成一個點菜運用的UI示例
- 分享一個iOS下完成根本繪畫板功效的簡略辦法
- 一個iOS上的秒表小運用的完成辦法分享
- iOS開發中運用Picker View完成一個點菜使用的UI示例
- iOS一個絲滑的全屏滑動前往手勢
- 第一個小順序雲筆記經過微信審核分享
- iOS 開發 處理UITableViewcell單選靜態改動cell文字和背景顏色的功用,且第一次默許選擇第一個cell
- (一)半小時開發一個APP
- IOS 完成一個死鎖招致 UI 假死的例子
- iOS 學習筆記(一) 視頻引導頁的制造