Scrapy+Flask+Mongodb+Swift 開發全攻略(1)

作者:葉孤城___
先一一介紹一下上面4個東西。第一個叫做Scrapy的東西是用python寫的爬蟲框架。
Flask是python寫的一個非常有名的web開發框架,python界有兩個名氣最大的web開發框架,Flask是其中之一,另一個叫做Django,為什麼不用Django的原因就是Django太龐大了,我們開發服務端並不需要render html之類的view層,只需要提供Restful接口,所以使用Django開發不是個明智的選擇,而且Django內置了很多多余的功能,而Flask比較精簡,很多額外的功能都可以通過安裝Flask的擴展來實現。
Mongodb是一個非關系型數據庫,它存儲數據的方式不同於mysql等關系型數據庫,是以key-value形式存取數據的,總的來說數據格式有點像json。和mysql各有優劣。我們這裡將會使用mongodb來做我們的數據庫。
Swift不多說了,iOS開發都懂得。
那麼,這個系列的教程到底是想干什麼呢?簡單來說,就是實現一個人完成獲得資源+編寫服務端+iOS客戶端+服務端部署上線+客戶端上AppStore。這是個漫長的過程,我也在學習過程中,可能過程中唯一輕松的就是iOS客戶端編寫的部分,所以我把這個部分放在最後,先做最難得。再做簡單的。
我之前是從來沒有寫過服務端的,只有大四的時候寫過一個月左右的JSP,那都是很多年前的老黃歷了,當時用的好像還是serverlet之類的東西。
所以用python編寫服務端我也是頭一遭。肯定漏洞百出,代碼極其ugly,不過他山之石,可以攻玉。每個人都可以在我寫這篇的過程中提出意見和建議。我們共同進步。
廢話不多說。我們開始第一步,寫一個爬蟲獲取我們需要的資源。
其實這裡的內容大部分學自我前幾天轉發的那篇blog
看過我blog的同學應該有印象,我年前的時候有用BeautifulSoup和urllib這兩個python框架寫過一個爬蟲,用來爬www.dbmeizi.com這個網站的美女圖片。那麼今天,我會用scrapy編寫一個功能更完整的爬蟲。他有如下幾個功能。
1.爬取dbmeizi.com上每個圖片的url和title。
2.把圖片url和title和一些自定義字段放在mongodb裡。
首先確保你的mac安裝了xcode的commandline工具和python界的cocoapods,叫做pip,還有mongodb(可以去官網下載)。
然後安裝scrapy這個python庫,很簡單。在Terminal裡運行sudo pip install scrapy,輸入密碼之後點擊回車。搞定。
我們的爬蟲爬完數據之後需要把數據存入mongodb,所以需要一個用來連接mongodb的第三方庫,這個庫叫做"pymongo",我們也可以用pip來安裝。
sudo pip install pymongo,就可以安裝了。
接下來,用scrapy startproject(這兩個單詞合起來是一個命令)來生成一個爬蟲。
輸入scrapy startprojct dbmeizi
然後scrapy幫我們生成了這麼一個模板。
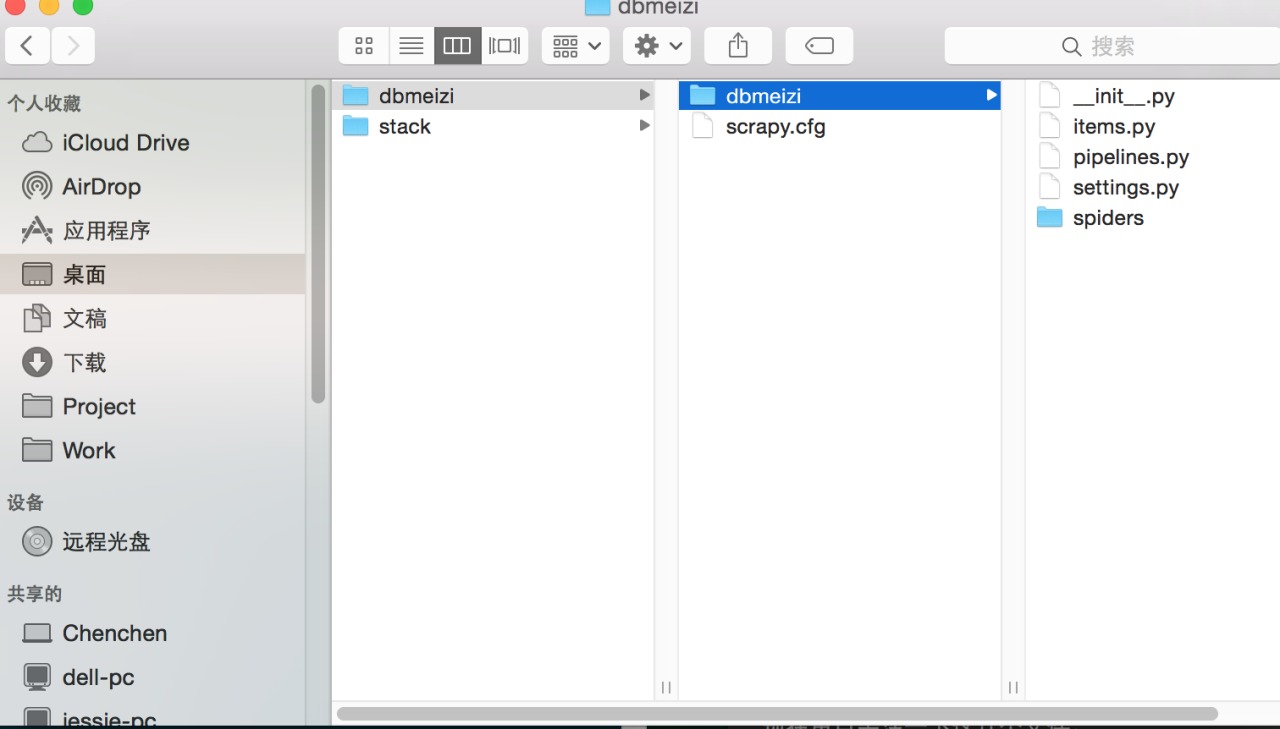
現在重點關注一下這幾個文件。
1.items.py,這裡你可以吧items.py看作是mvc中的model,在items裡我們定義了自己需要的模型。
2.piplines.py pipline俗稱管道,這個文件主要用來把我們獲取的item類型存入mongodb
3.spiders文件夾。 這裡用來存放我們的爬蟲文件。
4.settings.py 這裡需要設置一些常量,例如mongodb的數據庫名,數據庫地址和數據庫端口號等等。
第一步:定義Model層
我們可以先設想一下,dbmeizi.com這個網站,每一個美女圖片包括哪些內容?
我們先看一張圖。

這張圖顯示了dbmeizi.com這個網站裡每張圖片包含的信息。所以我們可以規定model有以下內容。
1.image的URL
2.image的title
3.可以設置一個star以後可以用來排序,讓用戶打分,看看哪個美女最受歡迎
4.還有一個id,防止後面插入數據庫的時候插入重復數據
ok,所以打開items.py我們修改後的代碼是這樣的。
from scrapy.item import Item, Field class MeiziItem(Item): # define the fields for your item here like: # name = scrapy.Field() datasrc = Field() title = Field() dataid = Field() startcount = Field()
我們定義了一個class叫做MeiziItem,繼承自scrapy的類Item,然後為我們的類定義了4個屬性,datasrc用來保存等下拉去的image-url,title用來保存圖片的title,dataid用來記錄圖片id防止重復圖片,starcount是喜歡次數,以後我們開發iOS端的時候可以設計一個喜歡的功能。每次用戶喜歡那麼startcount都+1.
第二步:編寫爬蟲
打開spiders文件夾,新建一個dbmeizi_scrapy.py文件。
在文件裡寫如下內容.
from scrapy import Spider
from scrapy.selector import Selector
from dbmeizi.items import MeiziItem
class dbmeiziSpider(Spider):
name = "dbmeiziSpider"
allowed_domin =["dbmeizi.com"]
start_urls = [
"http://www.dbmeizi.com",
]
def parse(self, response):
liResults = Selector(response).xpath('//li[@class="span3"]')
for li in liResults:
for img in li.xpath('.//img'):
item = MeiziItem()
item['title'] = img.xpath('@data-title').extract()
item['dataid'] = img.xpath('@data-id').extract()
item['datasrc'] = img.xpath('@data-src').extract()
item['startcount'] = 0
yield item可能很多人看到這就暈菜了。我盡量嘗試講的清楚明白。
首先我們定義了一個類名為dbmeiziSpider的類,繼承自Spider類,然後這個類有3個基礎的屬性,name表示這個爬蟲的名字,等一下我們在命令行狀態啟動爬蟲的時候,爬蟲的名字就是name規定的。
allowed_domin意思就是指在dbmeizi.com這個域名爬東西。
start_urls是一個數組,裡面用來保存需要爬的頁面,目前我們只需要爬首頁。所以只有一個地址。
然後def parse就是定義了一個parse方法(肯定是override的,我覺得父類裡肯定有一個同名方法),然後在這裡進行解析工作,這個方法有一個response參數,你可以把response想象成,scrapy這個框架在把start_urls裡的頁面下載了,然後response裡全部都是html代碼和css代碼。
然後,liResults = Selector(response).xpath('//li[@class="span3"]') 這句話什麼意思呢?
這句話的意思就是從html裡的最開始一直到最後,搜索所有class="span3"的li標簽。
我們獲得了li這個標簽後,再通過for img in li.xpath('.//img'):這個循環取出所有img標簽,最後一個for循環裡新建我們之前創建的MeiziItem,然後賦值。
如果實在看不懂,那麼你需要看兩個東西一個是xpath,一個是我之前寫的一片《iOS程序員寫爬蟲》那篇blog。
Ok,我們的爬蟲寫好了。
第三步:將我們的MeiziItem存入數據庫中
打開settings.py,我們修改成如下樣子。
BOT_NAME = 'dbmeizi' SPIDER_MODULES = ['dbmeizi.spiders'] NEWSPIDER_MODULE = 'dbmeizi.spiders' ITEM_PIPELINES = ['dbmeizi.pipelines.MongoDBPipeline',] MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "dbmeizi" MONGODB_COLLECTION = "meizi" # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'stack (+http://www.yourdomain.com)'
請注意ITEM_PIPELINES那個常數,這個常數是用來規定我們獲取爬蟲爬下來的數據並將之轉為model類型之後應該做什麼事。很簡單,這個常數告訴我們轉為model類型之後區pipelines.py裡找MongoDBPipeline這個class。這個class會替我們完成接下來的工作。
下面幾個MONGODB打頭的常數用來規定MONGODB的一些基本信息,比如server是哪個啊,端口是哪個之類的。
強烈建議自己去簡單的學習一下mongodb基礎知識。起碼會簡單的增刪改查,在mongodb的shell裡多練練,要不然完全看不懂。
在settings.py裡修改之後,我們打開pipelines.py。修改如下。
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Meizi added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item我們定義了一個類,名字叫做MongoDBPipeline,注意,這個名字是與我們在settings裡的ITEM_PIPELINES這個常數裡面規定的時一致的。注意別寫錯了。
init就是python中的構造方法,這個方法裡我們主要是建立於mongodb的鏈接,所以用上了pymongo這個框架。然後將一個collection作為類的一個屬性,在mongodb中,一個collection你可以想象成mysql中的一個table。
在process_item這個方法中,我們主要是將item存入數據庫。注意self.collection.insert(dict(item))這句話,就是將我們的MeiziItem存入數據庫。
ok,大功告成,我們現在運行一下。
1.啟動mongodb

2.運行爬蟲
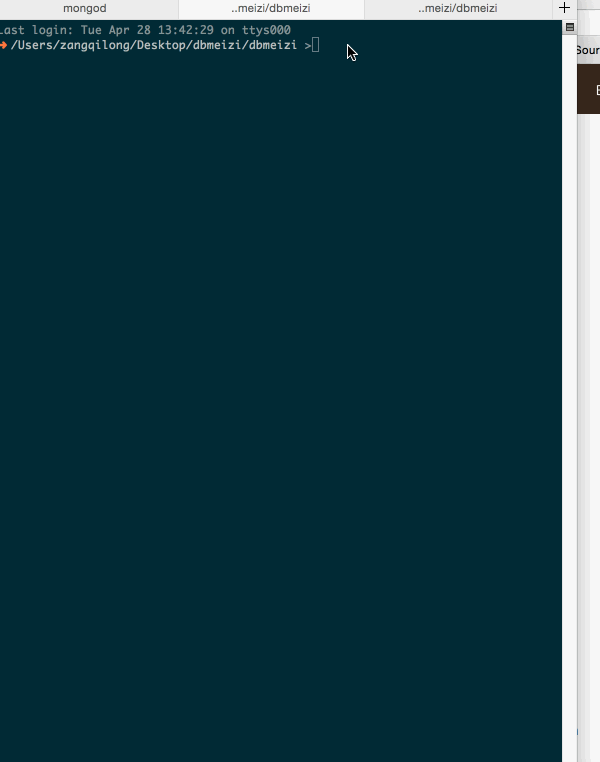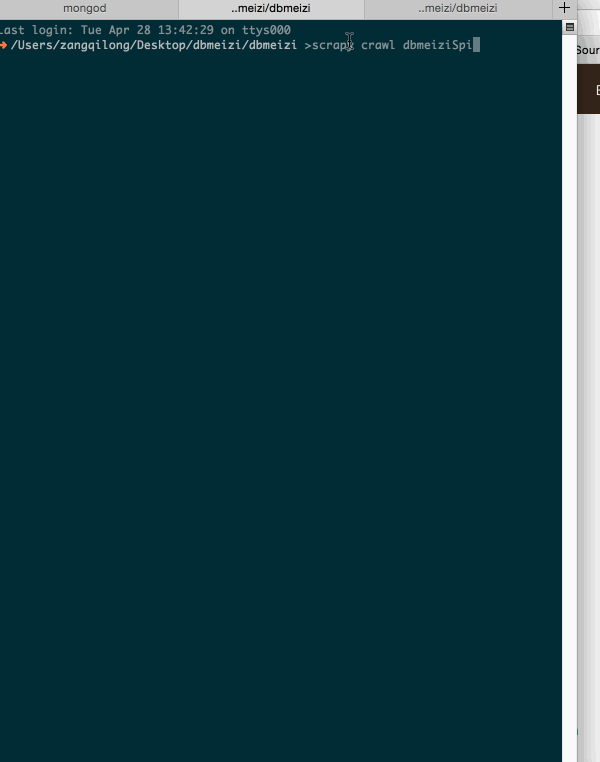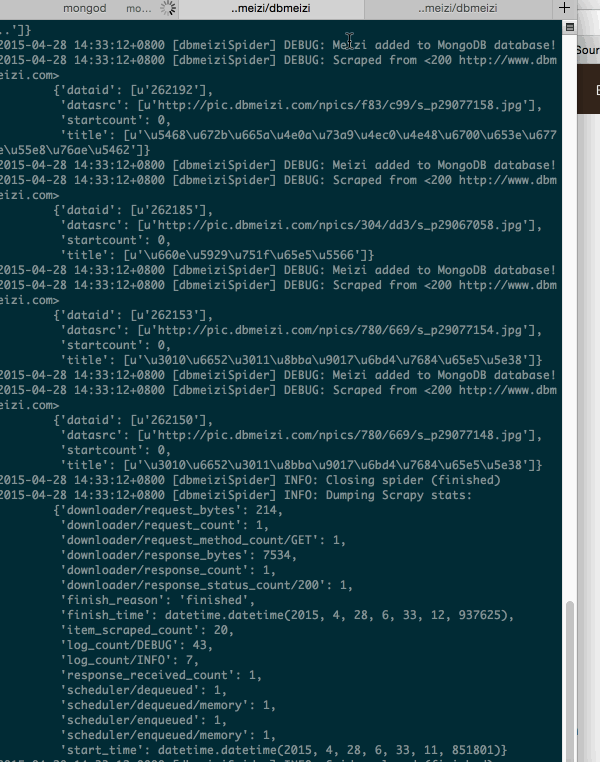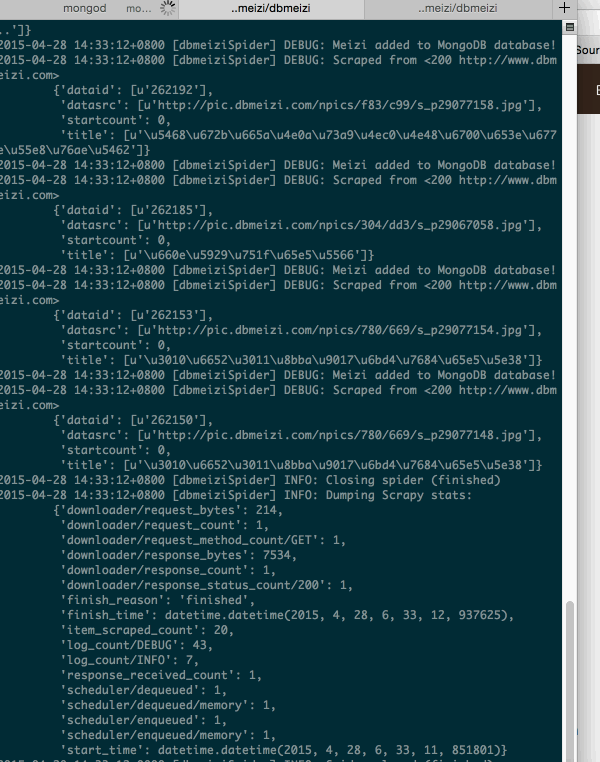
3.檢查我們的數據庫是否有數據
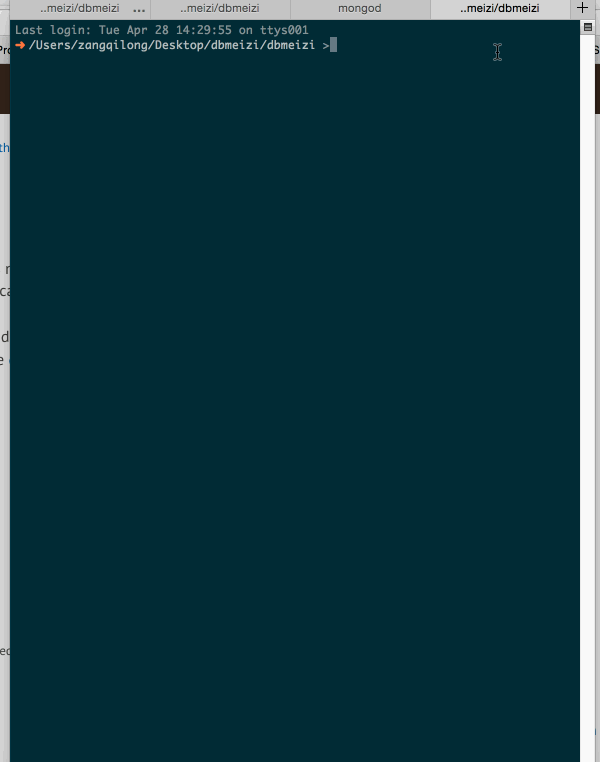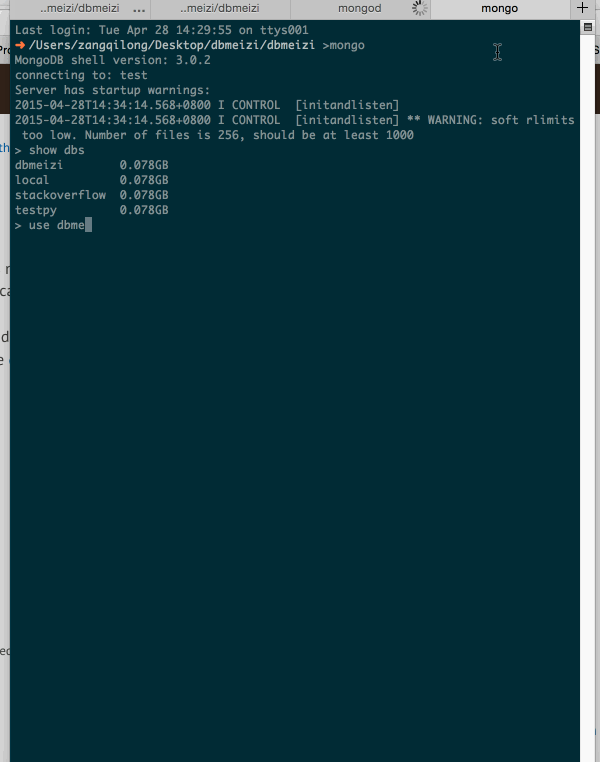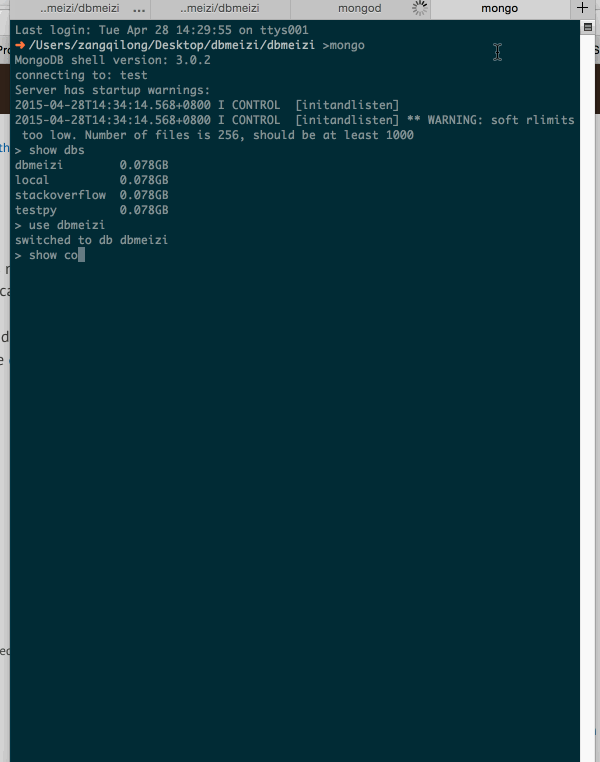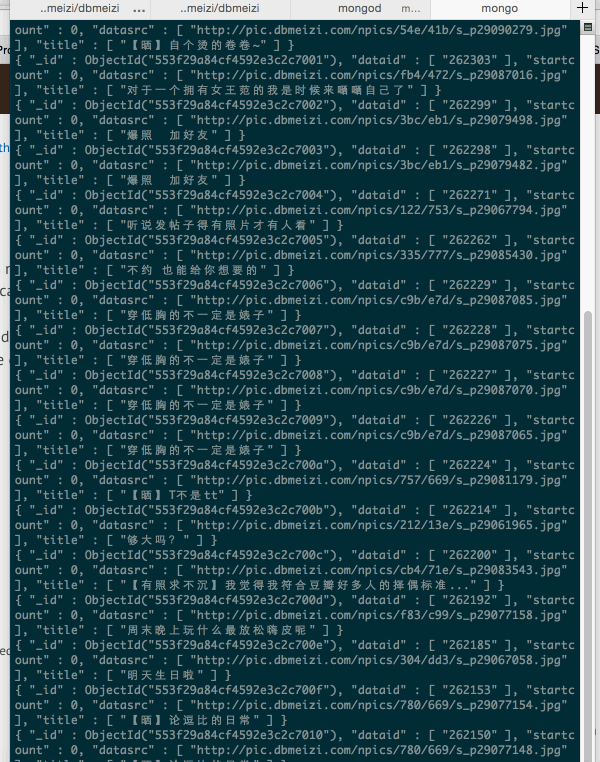
大功告成。
如果你編寫的爬蟲老是運行不了,首先檢查是否用pip安裝了需要的框架,或者哪裡寫錯了。
最後放上github地址:
https://github.com/zangqilong198812/DbMeiziScrapy



- Objective-C 代碼與Javascript 代碼互相挪用實例
- iOS開辟之UIScrollView控件詳解
- iOS10語音辨認框架SpeechFramework運用詳解
- iOS10 App適配權限 Push Notifications 字體Frame 碰到的成績
- iOS10適配之權限Crash成績的完善處理計劃
- iOS突變圓環扭轉動畫CAShapeLayer CAGradientLayer
- IOS CocoaPods詳解之制造篇
- IOS CocoaPods具體應用辦法
- IOS上iframe的轉動條掉效的處理方法
- iOS中NSArray數組經常使用處置方法
- iOS制造framework靜態庫圖文教程
- iOS開辟之用javascript挪用oc辦法而非url
- iOS中應用JSPatch框架使Objective-C與JavaScript代碼交互
- 實例講授iOS中的CATransition轉場動畫應用
- IOS CoreAnimation中layer動畫閃耀的處理辦法