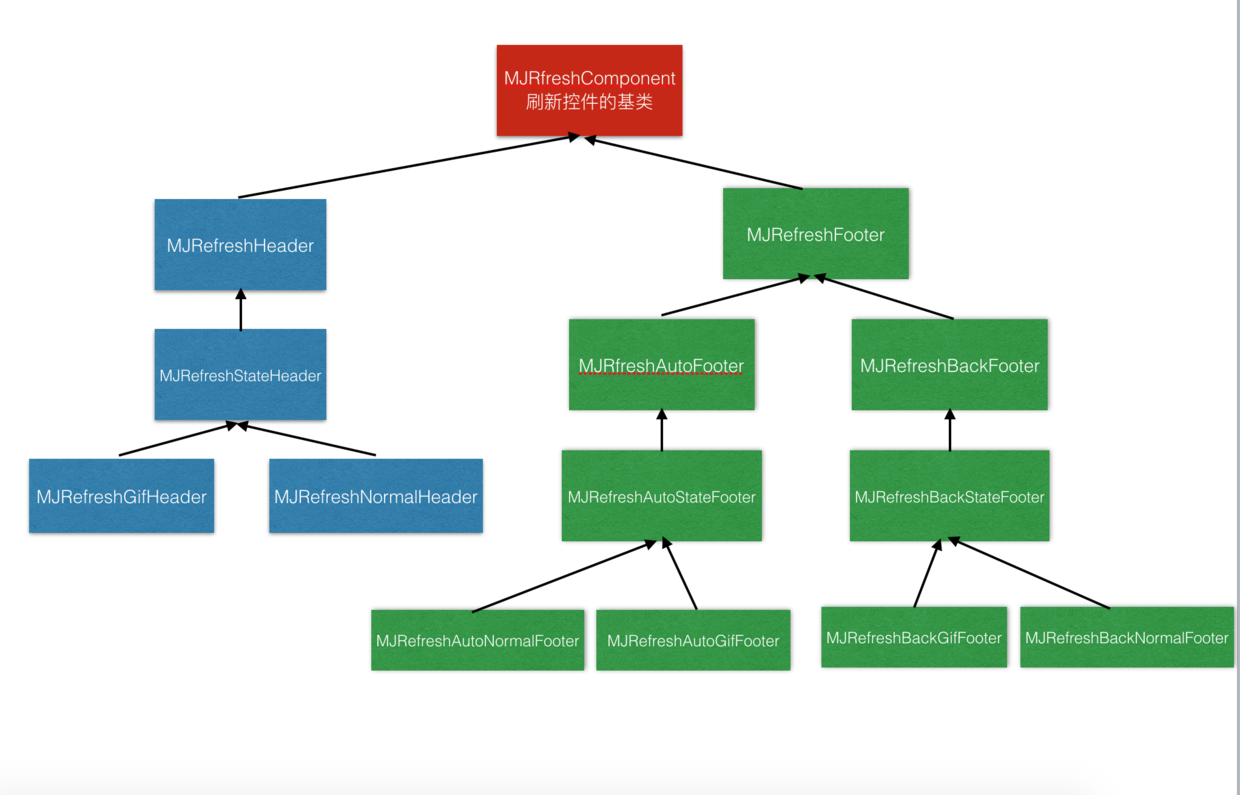
iOS 如何追蹤app
1.如何追蹤app崩潰率,如何解決線上閃退
當iOS設備上的App應用閃退時,操作系統會生成一個crash日志,保存在設備上。crash日志上有很多有用的信息,比如每個正在執行線程的完整堆棧跟蹤信息和內存映像,這樣就能夠通過解析這些信息進而定位crash發生時的代碼邏輯,從而找到App閃退的原因。通常來說,crash產生來源於兩種問題:違反iOS系統規則導致的crash和App代碼邏輯BUG導致的crash,下面分別對他們進行分析。
違反iOS系統規則產生crash的三種類型
(1) 內存報警閃退
當iOS檢測到內存過低時,它的VM系統會發出低內存警告通知,嘗試回收一些內存;如果情況沒有得到足夠的改善,iOS會終止後台應用以回收更多內存;最後,如果內存還是不足,那麼正在運行的應用可能會被終止掉。在Debug模式下,可以主動將客戶端執行的動作邏輯寫入一個log文件中,這樣程序童鞋可以將內存預警的邏輯寫入該log文件,當發生如下截圖中的內存報警時,就是提醒當前客戶端性能內存吃緊,可以通過Instruments工具中的Allocations 和 Leaks模塊庫來發現內存分配問題和內存洩漏問題。
(2) 響應超時
當應用程序對一些特定的事件(比如啟動、掛起、恢復、結束)響應不及時,蘋果的Watchdog機制會把應用程序干掉,並生成一份相應的crash日志。這些事件與下列UIApplicationDelegate方法相對應,當遇到Watchdog日志時,可以檢查上圖中的幾個方法是否有比較重的阻塞UI的動作。
application:didFinishLaunchingWithOptions:
applicationWillResignActive:
applicationDidEnterBackground:
applicationWillEnterForeground:
applicationDidBecomeActive:
applicationWillTerminate:
(3) 用戶強制退出
一看到“用戶強制退出”,首先可能想到的雙擊Home鍵,然後關閉應用程序。不過這種場景一般是不會產生crash日志的,因為雙擊Home鍵後,所有的應用程序都處於後台狀態,而iOS隨時都有可能關閉後台進程,當應用阻塞界面並停止響應時這種場景才會產生crash日志。這裡指的“用戶強制退出”場景,是稍微比較復雜點的操作:先按住電源鍵,直到出現“滑動關機”的界面時,再按住Home鍵,這時候當前應用程序會被終止掉,並且產生一份相應事件的crash日志。
應用邏輯的Bug
大多數閃退崩潰日志的產生都是因為應用中的Bug,這種Bug的錯誤種類有很多,比如
SEGV:(Segmentation Violation,段違例),無效內存地址,比如空指針,未初始化指針,棧溢出等;
SIGABRT:收到Abort信號,可能自身調用abort()或者收到外部發送過來的信號;
SIGBUS:總線錯誤。與SIGSEGV不同的是,SIGSEGV訪問的是無效地址(比如虛存映射不到物理內存),而SIGBUS訪問的是有效地址,但總線訪問異常(比如地址對齊問題);
SIGILL:嘗試執行非法的指令,可能不被識別或者沒有權限;
SIGFPE:Floating Point Error,數學計算相關問題(可能不限於浮點計算),比如除零操作;
SIGPIPE:管道另一端沒有進程接手數據;
常見的崩潰原因基本都是代碼邏輯問題或資源問題,比如數組越界,訪問野指針或者資源不存在,或資源大小寫錯誤等。
crash的收集
如果是在windows上你可以通過itools或pp助手等輔助工具查看系統產生的歷史crash日志,然後再根據app來查看。如果是在Mac 系統上,只需要打開xcode->windows->devices,選擇device logs進行查看,如下圖,這些crash文件都可以導出來,然後再單獨對這個crash文件做處理分析。
看日志
市場上已有的商業軟件提供crash收集服務,這些軟件基本都提供了日志存儲,日志符號化解析和服務端可視化管理等服務:
Crashlytics (www.crashlytics.com)
Crittercism (www.crittercism.com)
Bugsense (www.bugsense.com)
HockeyApp (www.hockeyapp.net)
Flurry(www.flurry.com)
開源的軟件也可以拿來收集crash日志,比如Razor,QuincyKit(git鏈接)等,這些軟件收集crash的原理其實大同小異,都是根據系統產生的crash日志進行了一次提取或封裝,然後將封裝後的crash文件上傳到對應的服務端進行解析處理。很多商業軟件都采用了Plcrashreporter這個開源工具來上傳和解析crash,比如HockeyApp,Flurry和crittercism等。
crash信息
由於自己的crash信息太長,找了一張示例:
1)crash標識是應用進程產生crash時的一些標識信息,它描述了該crash的唯一標識(E838FEFB-ECF6-498C-8B35-D40F0F9FEAE4),所發生的硬件設備類型(iphone3,1代表iphone4),以及App進程相關的信息等;
2)基本信息描述的是crash發生的時間和系統版本;
3)異常類型描述的是crash發生時拋出的異常類型和錯誤碼;
4)線程回溯描述了crash發生時所有線程的回溯信息,每個線程在每一幀對應的函數調用信息(這裡由於空間限制沒有全部列出);
5)二進制映像是指crash發生時已加載的二進制文件。以上就是一份crash日志包含的所有信息,接下來就需要根據這些信息去解析定位導致crash發生的代碼邏輯, 這就需要用到符號化解析的過程(洋名叫:symbolication)。
解決線上閃退
首先保證,發布前充分測試。發布後依然有閃退現象,查看崩潰日志,及時修復並發布。
2.什麼是事件響應鏈,點擊屏幕時是如何互動的,事件的傳遞。
事件響應鏈
對於IOS設備用戶來說,他們操作設備的方式主要有三種:觸摸屏幕、晃動設備、通過遙控設施控制設備。對應的事件類型有以下三種:
1、觸屏事件(Touch Event)
2、運動事件(Motion Event)
3、遠端控制事件(Remote-Control Event)
響應者鏈(Responder Chain)
響應者對象(Responder Object),指的是有響應和處理事件能力的對象。響應者鏈就是由一系列的響應者對象構成的一個層次結構。
UIResponder是所有響應對象的基類,在UIResponder類中定義了處理上述各種事件的接口。我們熟悉的UIApplication、 UIViewController、UIWindow和所有繼承自UIView的UIKit類都直接或間接的繼承自UIResponder,所以它們的實例都是可以構成響應者鏈的響應者對象。
響應者鏈有以下特點:
1、響應者鏈通常是由視圖(UIView)構成的;
2、一個視圖的下一個響應者是它視圖控制器(UIViewController)(如果有的話),然後再轉給它的父視圖(Super View);
3、視圖控制器(如果有的話)的下一個響應者為其管理的視圖的父視圖;
4、單例的窗口(UIWindow)的內容視圖將指向窗口本身作為它的下一個響應者
需要指出的是,Cocoa Touch應用不像Cocoa應用,它只有一個UIWindow對象,因此整個響應者鏈要簡單一點;
5、單例的應用(UIApplication)是一個響應者鏈的終點,它的下一個響應者指向nil,以結束整個循環。
點擊屏幕時是如何互動的
iOS系統檢測到手指觸摸(Touch)操作時會將其打包成一個UIEvent對象,並放入當前活動Application的事件隊列,單例的UIApplication會從事件隊列中取出觸摸事件並傳遞給單例的UIWindow來處理,UIWindow對象首先會使用hitTest:withEvent:方法尋找此次Touch操作初始點所在的視圖(View),即需要將觸摸事件傳遞給其處理的視圖,這個過程稱之為hit-test view。
UIWindow實例對象會首先在它的內容視圖上調用hitTest:withEvent:,此方法會在其視圖層級結構中的每個視圖上調用pointInside:withEvent:(該方法用來判斷點擊事件發生的位置是否處於當前視圖范圍內,以確定用戶是不是點擊了當前視圖),如果pointInside:withEvent:返回YES,則繼續逐級調用,直到找到touch操作發生的位置,這個視圖也就是要找的hit-test view。
hitTest:withEvent:方法的處理流程如下:首先調用當前視圖的pointInside:withEvent:方法判斷觸摸點是否在當前視圖內;若返回NO,則hitTest:withEvent:返回nil;若返回YES,則向當前視圖的所有子視圖(subviews)發送hitTest:withEvent:消息,所有子視圖的遍歷順序是從最頂層視圖一直到到最底層視圖,即從subviews數組的末尾向前遍歷,直到有子視圖返回非空對象或者全部子視圖遍歷完畢;若第一次有子視圖返回非空對象,則hitTest:withEvent:方法返回此對象,處理結束;如所有子視圖都返回非,則hitTest:withEvent:方法返回自身(self)。
事件的傳遞和響應分兩個鏈:
傳遞鏈:由系統向離用戶最近的view傳遞。UIKit –> active app’s event queue –> window –> root view –>……–>lowest view
響應鏈:由離用戶最近的view向系統傳遞。initial view –> super view –> …..–> view controller –> window –> Application
3.Run Loop是什麼,使用的目的,何時使用和關注點
Run Loop是一讓線程能隨時處理事件但不退出的機制。RunLoop 實際上是一個對象,這個對象管理了其需要處理的事件和消息,並提供了一個入口函數來執行Event Loop 的邏輯。線程執行了這個函數後,就會一直處於這個函數內部 “接受消息->等待->處理” 的循環中,直到這個循環結束(比如傳入 quit 的消息),函數返回。讓線程在沒有處理消息時休眠以避免資源占用、在有消息到來時立刻被喚醒。
OSX/iOS 系統中,提供了兩個這樣的對象:NSRunLoop 和 CFRunLoopRef。CFRunLoopRef 是在 CoreFoundation 框架內的,它提供了純 C 函數的 API,所有這些 API 都是線程安全的。NSRunLoop 是基於 CFRunLoopRef 的封裝,提供了面向對象的 API,但是這些 API 不是線程安全的。
線程和 RunLoop 之間是一一對應的,其關系是保存在一個全局的 Dictionary 裡。線程剛創建時並沒有 RunLoop,如果你不主動獲取,那它一直都不會有。RunLoop 的創建是發生在第一次獲取時,RunLoop 的銷毀是發生在線程結束時。你只能在一個線程的內部獲取其 RunLoop(主線程除外)。
系統默認注冊了5個Mode:
kCFRunLoopDefaultMode: App的默認 Mode,通常主線程是在這個 Mode 下運行的。
UITrackingRunLoopMode: 界面跟蹤 Mode,用於 ScrollView 追蹤觸摸滑動,保證界面滑動時不受其他 Mode 影響。
UIInitializationRunLoopMode: 在剛啟動 App 時第進入的第一個 Mode,啟動完成後就不再使用。
GSEventReceiveRunLoopMode: 接受系統事件的內部 Mode,通常用不到。
kCFRunLoopCommonModes: 這是一個占位的 Mode,沒有實際作用。
Run Loop的四個作用:
使程序一直運行接受用戶輸入
決定程序在何時應該處理哪些Event
調用解耦
節省CPU時間
主線程的run loop默認是啟動的。iOS的應用程序裡面,程序啟動後會有一個如下的main() 函數:
int main(int argc, char *argv[])
{
@autoreleasepool {
return UIApplicationMain(argc, argv, nil, NSStringFromClass([appDelegate class]));
}
}
重點是UIApplicationMain() 函數,這個方法會為main thread 設置一個NSRunLoop 對象,這就解釋了本文開始說的為什麼我們的應用可以在無人操作的時候休息,需要讓它干活的時候又能立馬響應。
對其它線程來說,run loop默認是沒有啟動的,如果你需要更多的線程交互則可以手動配置和啟動,如果線程只是去執行一個長時間的已確定的任務則不需要。在任何一個Cocoa程序的線程中,都可以通過:
NSRunLoop *runloop = [NSRunLoop currentRunLoop];
來獲取到當前線程的run loop。
一個run loop就是一個事件處理循環,用來不停的監聽和處理輸入事件並將其分配到對應的目標上進行處理。
NSRunLoop是一種更加高明的消息處理模式,他就高明在對消息處理過程進行了更好的抽象和封裝,這樣才能是的你不用處理一些很瑣碎很低層次的具體消息的處理,在NSRunLoop中每一個消息就被打包在input source或者是timer source中了。使用run loop可以使你的線程在有工作的時候工作,沒有工作的時候休眠,這可以大大節省系統資源。
RunLoop
什麼時候使用run loop
僅當在為你的程序創建輔助線程的時候,你才需要顯式運行一個run loop。Run loop是程序主線程基礎設施的關鍵部分。所以,Cocoa和Carbon程序提供了代碼運行主程序的循環並自動啟動run loop。IOS程序中UIApplication的run方法(或Mac OS X中的NSApplication)作為程序啟動步驟的一部分,它在程序正常啟動的時候就會啟動程序的主循環。類似的,RunApplicationEventLoop函數為Carbon程序啟動主循環。如果你使用xcode提供的模板創建你的程序,那你永遠不需要自己去顯式的調用這些例程。
對於輔助線程,你需要判斷一個run loop是否是必須的。如果是必須的,那麼你要自己配置並啟動它。你不需要在任何情況下都去啟動一個線程的run loop。比如,你使用線程來處理一個預先定義的長時間運行的任務時,你應該避免啟動run loop。Run loop在你要和線程有更多的交互時才需要,比如以下情況:
使用端口或自定義輸入源來和其他線程通信
使用線程的定時器
Cocoa中使用任何performSelector…的方法
使線程周期性工作
關注點
Cocoa中的NSRunLoop類並不是線程安全的
我們不能再一個線程中去操作另外一個線程的run loop對象,那很可能會造成意想不到的後果。不過幸運的是CoreFundation中的不透明類CFRunLoopRef是線程安全的,而且兩種類型的run loop完全可以混合使用。Cocoa中的NSRunLoop類可以通過實例方法:
(CFRunLoopRef)getCFRunLoop;獲取對應的CFRunLoopRef類,來達到線程安全的目的。
Run loop的管理並不完全是自動的。
我們仍必須設計線程代碼以在適當的時候啟動run loop並正確響應輸入事件,當然前提是線程中需要用到run loop。而且,我們還需要使用while/for語句來驅動run loop能夠循環運行,下面的代碼就成功驅動了一個run loop:
BOOL isRunning = NO;
do {
isRunning = [[NSRunLoop currentRunLoop] runMode:NSDefaultRunLoopMode beforeDate:[NSDatedistantFuture]];
} while (isRunning);
Run loop同時也負責autorelease pool的創建和釋放
在使用手動的內存管理方式的項目中,會經常用到很多自動釋放的對象,如果這些對象不能夠被即時釋放掉,會造成內存占用量急劇增大。Run loop就為我們做了這樣的工作,每當一個運行循環結束的時候,它都會釋放一次autorelease pool,同時pool中的所有自動釋放類型變量都會被釋放掉。
ARC和MRCObjective-c中提供了兩種內存管理機制MRC(MannulReference Counting)和ARC(Automatic Reference Counting),分別提供對內存的手動和自動管理,來滿足不同的需求。Xcode 4.1及其以前版本沒有ARC。
在MRC的內存管理模式下,與對變量的管理相關的方法有:retain,release和autorelease。retain和release方法操作的是引用記數,當引用記數為零時,便自動釋放內存。並且可以用NSAutoreleasePool對象,對加入自動釋放池(autorelease調用)的變量進行管理,當drain時回收內存。
(1) retain,該方法的作用是將內存數據的所有權附給另一指針變量,引用數加1,即retainCount+= 1;
(2) release,該方法是釋放指針變量對內存數據的所有權,引用數減1,即retainCount-= 1;
(3) autorelease,該方法是將該對象內存的管理放到autoreleasepool中。
在ARC中與內存管理有關的標識符,可以分為變量標識符和屬性標識符,對於變量默認為__strong,而對於屬性默認為unsafe_unretained。也存在autoreleasepool。
其中assign/retain/copy與MRC下property的標識符意義相同,strong類似與retain,assign類似於unsafe_unretained,strong/weak/unsafe_unretained與ARC下變量標識符意義相同,只是一個用於屬性的標識,一個用於變量的標識(帶兩個下劃短線__)。所列出的其他的標識符與MRC下意義相同。
線程和進程進程,是並發執行的程序在執行過程中分配和管理資源的基本單位,是一個動態概念,竟爭計算機系統資源的基本單位。每一個進程都有一個自己的地址空間,即進程空間或(虛空間)。進程空間的大小 只與處理機的位數有關,一個 16 位長處理機的進程空間大小為 216 ,而 32 位處理機的進程空間大小為 232 。進程至少有 5 種基本狀態,它們是:初始態,執行態,等待狀態,就緒狀態,終止狀態。
線程,在網絡或多用戶環境下,一個服務器通常需要接收大量且不確定數量用戶的並發請求,為每一個請求都創建一個進程顯然是行不通的,——無論是從系統資源開銷方面或是響應用戶請求的效率方面來看。因此,操作系統中線程的概念便被引進了。線程,是進程的一部分,一個沒有線程的進程可以被看作是單線程的。線程有時又被稱為輕權進程或輕量級進程,也是 CPU 調度的一個基本單位。
進程的執行過程是線狀的,盡管中間會發生中斷或暫停,但該進程所擁有的資源只為該線狀執行過程服務。一旦發生進程上下文切換,這些資源都是要被保護起來的。這是進程宏觀上的執行過程。而進程又可有單線程進程與多線程進程兩種。我們知道,進程有 一個進程控制塊 PCB ,相關程序段 和 該程序段對其進行操作的數據結構集 這三部分,單線程進程的執行過程在宏觀上是線性的,微觀上也只有單一的執行過程;而多線程進程在宏觀上的執行過程同樣為線性的,但微觀上卻可以有多個執行操作(線程),如不同代碼片段以及相關的數據結構集。線程的改變只代表了 CPU 執行過程的改變,而沒有發生進程所擁有的資源變化。除了 CPU 之外,計算機內的軟硬件資源的分配與線程無關,線程只能共享它所屬進程的資源。與進程控制表和 PCB 相似,每個線程也有自己的線程控制表 TCB ,而這個 TCB 中所保存的線程狀態信息則要比 PCB 表少得多,這些信息主要是相關指針用堆棧(系統棧和用戶棧),寄存器中的狀態數據。進程擁有一個完整的虛擬地址空間,不依賴於線程而獨立存在;反之,線程是進程的一部分,沒有自己的地址空間,與進程內的其他線程一起共享分配給該進程的所有資源。
線程可以有效地提高系統的執行效率,但並不是在所有計算機系統中都是適用的,如某些很少做進程調度和切換的實時系統。使用線程的好處是有多個任務需要處理機處理時,減少處理機的切換時間;而且,線程的創建和結束所需要的系統開銷也比進程的創建和結束要小得多。最適用使用線程的系統是多處理機系統和網絡系統或分布式系統。
平常常用的多線程處理方式及優缺點iOS有四種多線程編程的技術,分別是:NSThread,Cocoa NSOperation,GCD(全稱:Grand Central Dispatch),pthread。
四種方式的優缺點介紹:
1)NSThread優點:NSThread 比其他兩個輕量級。缺點:需要自己管理線程的生命周期,線程同步。線程同步對數據的加鎖會有一定的系統開銷。
2)Cocoa NSOperation優點:不需要關心線程管理, 數據同步的事情,可以把精力放在自己需要執行的操作上。Cocoa operation相關的類是NSOperation, NSOperationQueue.NSOperation是個抽象類,使用它必須用它的子類,可以實現它或者使用它定義好的兩個子類: NSInvocationOperation和NSBlockOperation.創建NSOperation子類的對象,把對象添加到NSOperationQueue隊列裡執行。
3)GCD(全優點)Grand Central dispatch(GCD)是Apple開發的一個多核編程的解決方案。在iOS4.0開始之後才能使用。GCD是一個替代NSThread, NSOperationQueue,NSInvocationOperation等技術的很高效強大的技術。
4) pthread是一套通用的多線程API,適用於Linux\Windows\Unix,跨平台,可移植,使用C語言,生命周期需要程序員管理,IOS開發中使用很少。
GCD線程死鎖
GCD 確實好用 ,很強大,相比NSOpretion 無法提供 取消任務的功能。
如此強大的工具用不好可能會出現線程死鎖。 如下代碼:
[super viewDidLoad];
NSLog(@”=================4”);
dispatch_sync(dispatch_get_main_queue(),
^{ NSLog(@”=================5”); });
NSLog(@”=================6”);
}
GCD Queue 分為三種:
1,The main queue :主隊列,主線程就是在個隊列中。
2,Global queues : 全局並發隊列。
3,用戶隊列:是用函數 dispatch_queue_create創建的自定義隊列
dispatch_sync 和 dispatch_async 區別:
dispatch_async(queue,block) async 異步隊列,dispatch_async函數會立即返回, block會在後台異步執行。
dispatch_sync(queue,block) sync 同步隊列,dispatch_sync函數不會立即返回,及阻塞當前線程,等待 block同步執行完成。
分析上面代碼:
viewDidLoad 在主線程中, 及在dispatch_get_main_queue() 中,執行到sync 時 向dispatch_get_main_queue()插入 同步 threed。sync 會等到 後面block 執行完成才返回, sync 又再 dispatch_get_main_queue() 隊列中,它是串行隊列,sync 是後加入的,前一個是主線程,所以 sync 想執行 block 必須等待主線程執行完成,主線程等待 sync 返回,去執行後續內容。照成死鎖,sync 等待mainThread 執行完成, mianThread 等待sync 函數返回。下面例子:
(void)viewDidLoad{[super viewDidLoad];
dispatch_async(dispatch_get_global_queue(0, 0), ^{
NSLog(@”=================1”);
dispatch_sync(dispatch_get_main_queue(), ^{
NSLog(@”=================2”); });
NSLog(@”=================3”); });
}
程序會完成執行,為什麼不會出現死鎖。
首先: async 在主線程中 創建了一個異步線程 加入 全局並發隊列,async 不會等待block 執行完成,立即返回,
1,async 立即返回, viewDidLoad 執行完畢,及主線程執行完畢。
2,同時,全局並發隊列立即執行異步 block , 打印 1, 當執行到 sync 它會等待 block 執行完成才返回, 及等待dispatch_get_main_queue() 隊列中的 mianThread 執行完成, 然後才開始調用block 。因為1 和 2 幾乎同時執行,因為2 在全局並發隊列上, 2 中執行到sync 時 1 可能已經執行完成或 等了一會,mainThread 很快退出, 2 等已執行後繼續內容。如果阻塞了主線程,2 中的sync 就無法執行啦,mainThread 永遠不會退出, sync 就永遠等待著。
大量數據表的優化方案1.對查詢進行優化,要盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。
2.應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如:
select id from t where num is null
最好不要給數據庫留NULL,盡可能的使用 NOT NULL填充數據庫.
備注、描述、評論之類的可以設置為 NULL,其他的,最好不要使用NULL。
不要以為 NULL 不需要空間,比如:char(100) 型,在字段建立時,空間就固定了, 不管是否插入值(NULL也包含在內),都是占用 100個字符的空間的,如果是varchar這樣的變長字段, null 不占用空間。
可以在num上設置默認值0,確保表中num列沒有null值,然後這樣查詢:
select id from t where num=0
3.應盡量避免在 where 子句中使用 != 或 <> 操作符,否則將引擎放棄使用索引而進行全表掃描。
4.應盡量避免在 where 子句中使用 or 來連接條件,如果一個字段有索引,一個字段沒有索引,將導致引擎放棄使用索引而進行全表掃描,如:
select id from t where num=10 or Name=’admin’
可以這樣查詢:
select id from t where num=10 union all select id from t where Name=’admin’
5.in 和 not in 也要慎用,否則會導致全表掃描,如:
select id from t where num in (1,2,3)
對於連續的數值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
很多時候用 exists 代替 in 是一個好的選擇:
select num from a where num in (select num from b)
用下面的語句替換:
select num from a where exists (select 1 from b where num=a.num)
6.下面的查詢也將導致全表掃描:
select id from t where name like ‘%abc%’
若要提高效率,可以考慮全文檢索。
7.如果在 where 子句中使用參數,也會導致全表掃描。因為SQL只有在運行時才會解析局部變量,但優化程序不能將訪問計劃的選擇推遲到運行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變量的值還是未知的,因而無法作為索引選擇的輸入項。如下面語句將進行全表掃描:
select id from t where num=@num
可以改為強制查詢使用索引:
select id from t with (index(索引名)) where num=@num
應盡量避免在 where 子句中對字段進行表達式操作,這將導致引擎放棄使用索引而進行全表掃描。如:
select id from t where num/2=100
應改為:
select id from t where num=100*2
9.應盡量避免在where子句中對字段進行函數操作,這將導致引擎放棄使用索引而進行全表掃描。如:
select id from t where substring(name,1,3)=’abc’ -–name以abc開頭的id
select id from t where datediff(day,createdate,’2015-11-30′)=0 -–‘2015-11-30’ –生成的id
應改為:
select id from t where name like’abc%’
select id from t where createdate>=’2005-11-30’ and createdate<’2005-12-1’
10.不要在 where 子句中的“=”左邊進行函數、算術運算或其他表達式運算,否則系統將可能無法正確使用索引。
11.在使用索引字段作為條件時,如果該索引是復合索引,那麼必須使用到該索引中的第一個字段作為條件時才能保證系統使用該索引,否則該索引將不會被使用,並且應盡可能的讓字段順序與索引順序相一致。
12.不要寫一些沒有意義的查詢,如需要生成一個空表結構:
select col1,col2 into #t from t where1=0
這類代碼不會返回任何結果集,但是會消耗系統資源的,應改成這樣:
create table #t(…)
13.Update 語句,如果只更改1、2個字段,不要Update全部字段,否則頻繁調用會引起明顯的性能消耗,同時帶來大量日志。
14.對於多張大數據量(這裡幾百條就算大了)的表JOIN,要先分頁再JOIN,否則邏輯讀會很高,性能很差。
15.select count(*) from table;這樣不帶任何條件的count會引起全表掃描,並且沒有任何業務意義,是一定要杜絕的。
16.索引並不是越多越好,索引固然可以提高相應的 select 的效率,但同時也降低了 insert 及 update 的效率,因為 insert 或 update 時有可能會重建索引,所以怎樣建索引需要慎重考慮,視具體情況而定。一個表的索引數最好不要超過6個,若太多則應考慮一些不常使用到的列上建的索引是否有 必要。
17.應盡可能的避免更新 clustered 索引數據列,因為 clustered 索引數據列的順序就是表記錄的物理存儲順序,一旦該列值改變將導致整個表記錄的順序的調整,會耗費相當大的資源。若應用系統需要頻繁更新 clustered 索引數據列,那麼需要考慮是否應將該索引建為 clustered 索引。
18.盡量使用數字型字段,若只含數值信息的字段盡量不要設計為字符型,這會降低查詢和連接的性能,並會增加存儲開銷。這是因為引擎在處理查詢和連 接時會逐個比較字符串中每一個字符,而對於數字型而言只需要比較一次就夠了。
19.盡可能的使用 varchar/nvarchar 代替 char/nchar ,因為首先變長字段存儲空間小,可以節省存儲空間,其次對於查詢來說,在一個相對較小的字段內搜索效率顯然要高些。
20.任何地方都不要使用
select * from t
用具體的字段列表代替“*”,不要返回用不到的任何字段。
21.盡量使用表變量來代替臨時表。如果表變量包含大量數據,請注意索引非常有限(只有主鍵索引)。
22.避免頻繁創建和刪除臨時表,以減少系統表資源的消耗。臨時表並不是不可使用,適當地使用它們可以使某些例程更有效,例如,當需要重復引用大型表或常用表中的某個數據集時。但是,對於一次性事件, 最好使用導出表。
23.在新建臨時表時,如果一次性插入數據量很大,那麼可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果數據量不大,為了緩和系統表的資源,應先create table,然後insert。
24.如果使用到了臨時表,在存儲過程的最後務必將所有的臨時表顯式刪除,先 truncate table ,然後 drop table ,這樣可以避免系統表的較長時間鎖定。
25.盡量避免使用游標,因為游標的效率較差,如果游標操作的數據超過1萬行,那麼就應該考慮改寫。
26.使用基於游標的方法或臨時表方法之前,應先尋找基於集的解決方案來解決問題,基於集的方法通常更有效。
27.與臨時表一樣,游標並不是不可使用。對小型數據集使用 FAST_FORWARD 游標通常要優於其他逐行處理方法,尤其是在必須引用幾個表才能獲得所需的數據時。在結果集中包括“合計”的例程通常要比使用游標執行的速度快。如果開發時 間允許,基於游標的方法和基於集的方法都可以嘗試一下,看哪一種方法的效果更好。
28.在所有的存儲過程和觸發器的開始處設置 SET NOCOUNT ON ,在結束時設置 SET NOCOUNT OFF 。無需在執行存儲過程和觸發器的每個語句後向客戶端發送 DONE_IN_PROC 消息。
29.盡量避免大事務操作,提高系統並發能力。
30.盡量避免向客戶端返回大數據量,若數據量過大,應該考慮相應需求是否合理。
實際案例分析:拆分大的 DELETE 或INSERT 語句,批量提交SQL語句
如果你需要在一個在線的網站上去執行一個大的 DELETE 或 INSERT 查詢,你需要非常小心,要避免你的操作讓你的整個網站停止相應。因為這兩個操作是會鎖表的,表一鎖住了,別的操作都進不來了。
Apache 會有很多的子進程或線程。所以,其工作起來相當有效率,而我們的服務器也不希望有太多的子進程,線程和數據庫鏈接,這是極大的占服務器資源的事情,尤其是內存。
如果你把你的表鎖上一段時間,比如30秒鐘,那麼對於一個有很高訪問量的站點來說,這30秒所積累的訪問進程/線程,數據庫鏈接,打開的文件數,可能不僅僅會讓你的WEB服務崩潰,還可能會讓你的整台服務器馬上掛了。
所以,如果你有一個大的處理,你一定把其拆分,使用 LIMIT oracle(rownum),sqlserver(top)條件是一個好的方法。下面是一個mysql示例:
while(1){//每次只做1000條
mysql_query(“delete from logs where log_date <= ’2015-11-01’ limit 1000”);
if(mysql_affected_rows() == 0){//刪除完成,退出!break;
}//每次暫停一段時間,釋放表讓其他進程/線程訪問。
usleep(50000)
}
8. 常用到的動畫庫
Facebook 開源動畫庫 Pop 的 GitHub 主頁:facebook/pop · GitHub,介紹:Playing with Pop (i)
Canvas 項目主頁:Canvas – Simplify iOS Development,介紹:Animate in Xcode Without Code
拿 Canvas 來和 Pop 比其實不大合適,雖然兩者都自稱「動畫庫」,但是「庫」這個詞的含義有所區別。本質上 Canvas 是一個「動畫合集」而 Pop 是一個「動畫引擎」。
先說 Canvas。Canvas 的目的是「Animate in Xcode Without Code」。開發者可以通過在 Storyboard 中指定 User Defined Runtime Attributes 來實現一些 Canvas 中預設的動畫,也就是他網站上能看到的那些。但是除了更改動畫的 delay 和 duration 基本上不能調整其他的參數。
Pop 就不一樣了。如果說 Canvas 是對 Core Animation 的封裝,Pop 則是對 Core Animation(以及 UIDynamics)的再實現。
Pop 語法上和 Core Animation 相似,效果上則不像 Canvas 那麼生硬(時間四等分,振幅硬編碼)。這使得對 Core Animation 有了解的程序員可以很輕松地把原來的「靜態動畫」轉換成「動態動畫」。
同時 Pop 又往前多走了一步。既然動畫的本質是根據時間函數來做插值,那麼理論上任何一個對象的任何一個值都可以用來做插值,而不僅僅是 Core Animation 裡定死的那一堆大小、位移、旋轉、縮放等 animatable properties。
Restful架構REST是一種架構風格,其核心是面向資源,REST專門針對網絡應用設計和開發方式,以降低開發的復雜性,提高系統的可伸縮性。REST提出設計概念和准則為:
1.網絡上的所有事物都可以被抽象為資源(resource)
2.每一個資源都有唯一的資源標識(resource identifier),對資源的操作不會改變這些標識
3.所有的操作都是無狀態的
REST簡化開發,其架構遵循CRUD原則,該原則告訴我們對於資源(包括網絡資源)只需要四種行為:創建,獲取,更新和刪除就可以完成相關的操作和處理。您可以通過統一資源標識符(Universal Resource Identifier,URI)來識別和定位資源,並且針對這些資源而執行的操作是通過 HTTP 規范定義的。其核心操作只有GET,PUT,POST,DELETE。
由於REST強制所有的操作都必須是stateless的,這就沒有上下文的約束,如果做分布式,集群都不需要考慮上下文和會話保持的問題。極大的提高系統的可伸縮性。
RESTful架構:
(1)每一個URI代表一種資源;
(2)客戶端和服務器之間,傳遞這種資源的某種表現層;
(3)客戶端通過四個HTTP動詞,對服務器端資源進行操作,實現”表現層狀態轉化”。
這個類庫提供一個UIImageView類別以支持加載來自網絡的遠程圖片。具有緩存管理、異步下載、同一個URL下載次數控制和優化等特征。
SDWebImage 加載圖片的流程
1.入口 setImageWithURL:placeholderImage:options: 會先把 placeholderImage 顯示,然後 SDWebImageManager 根據 URL 開始處理圖片。
2.進入 SDWebImageManager-downloadWithURL:delegate:options:userInfo:,交給 SDImageCache 從緩存查找圖片是否已經下載 queryDiskCacheForKey:delegate:userInfo:.
3.先從內存圖片緩存查找是否有圖片,如果內存中已經有圖片緩存,SDImageCacheDelegate 回調 imageCache:didFindImage:forKey:userInfo: 到 SDWebImageManager。
4.SDWebImageManagerDelegate 回調 webImageManager:didFinishWithImage: 到 UIImageView+WebCache 等前端展示圖片。
5.如果內存緩存中沒有,生成 NSInvocationOperation 添加到隊列開始從硬盤查找圖片是否已經緩存。
6.根據 URLKey 在硬盤緩存目錄下嘗試讀取圖片文件。這一步是在 NSOperation 進行的操作,所以回主線程進行結果回調 notifyDelegate:。
7.如果上一操作從硬盤讀取到了圖片,將圖片添加到內存緩存中(如果空閒內存過小,會先清空內存緩存)。SDImageCacheDelegate 回調 imageCache:didFindImage:forKey:userInfo:。進而回調展示圖片。
8.如果從硬盤緩存目錄讀取不到圖片,說明所有緩存都不存在該圖片,需要下載圖片,回調 imageCache:didNotFindImageForKey:userInfo:。
9.共享或重新生成一個下載器 SDWebImageDownloader 開始下載圖片。
10.圖片下載由 NSURLConnection 來做,實現相關 delegate 來判斷圖片下載中、下載完成和下載失敗。
11.connection:didReceiveData: 中利用 ImageIO 做了按圖片下載進度加載效果。
12.connectionDidFinishLoading: 數據下載完成後交給 SDWebImageDecoder 做圖片解碼處理。
13.圖片解碼處理在一個 NSOperationQueue 完成,不會拖慢主線程 UI。如果有需要對下載的圖片進行二次處理,最好也在這裡完成,效率會好很多。
14.在主線程 notifyDelegateOnMainThreadWithInfo: 宣告解碼完成,imageDecoder:didFinishDecodingImage:userInfo: 回調給 SDWebImageDownloader。
15.imageDownloader:didFinishWithImage: 回調給 SDWebImageManager 告知圖片下載完成。
16.通知所有的 downloadDelegates 下載完成,回調給需要的地方展示圖片。
17.將圖片保存到 SDImageCache 中,內存緩存和硬盤緩存同時保存。寫文件到硬盤也在以單獨 NSInvocationOperation 完成,避免拖慢主線程。
18.SDImageCache 在初始化的時候會注冊一些消息通知,在內存警告或退到後台的時候清理內存圖片緩存,應用結束的時候清理過期圖片。
19.SDWI 也提供了 UIButton+WebCache 和 MKAnnotationView+WebCache,方便使用。
20.SDWebImagePrefetcher 可以預先下載圖片,方便後續使用。
SDWebImage庫的作用
通過對UIImageView的類別擴展來實現異步加載替換圖片的工作。
主要用到的對象:
1、UIImageView (WebCache)類別,入口封裝,實現讀取圖片完成後的回調
2、SDWebImageManager,對圖片進行管理的中轉站,記錄那些圖片正在讀取。
向下層讀取Cache(調用SDImageCache),或者向網絡讀取對象(調用SDWebImageDownloader) 。
實現SDImageCache和SDWebImageDownloader的回調。
3、SDImageCache,根據URL的MD5摘要對圖片進行存儲和讀取(實現存在內存中或者存在硬盤上兩種實現)
實現圖片和內存清理工作。
4、SDWebImageDownloader,根據URL向網絡讀取數據(實現部分讀取和全部讀取後再通知回調兩種方式)
其他類:
SDWebImageDecoder,異步對圖像進行了一次解壓??
1、SDImageCache是怎麼做數據管理的?
SDImageCache分兩個部分,一個是內存層面的,一個是硬盤層面的。內存層面的相當是個緩存器,以Key-Value的形式存儲圖片。當內存不夠的時候會清除所有緩存圖片。用搜索文件系統的方式做管理,文件替換方式是以時間為單位,剔除時間大於一周的圖片文件。當SDWebImageManager向SDImageCache要資源時,先搜索內存層面的數據,如果有直接返回,沒有的話去訪問磁盤,將圖片從磁盤讀取出來,然後做Decoder,將圖片對象放到內存層面做備份,再返回調用層。
2、為啥必須做Decoder?
由於UIImage的imageWithData函數是每次畫圖的時候才將Data解壓成ARGB的圖像,所以在每次畫圖的時候,會有一個解壓操作,這樣效率很低,但是只有瞬時的內存需求。為了提高效率通過SDWebImageDecoder將包裝在Data下的資源解壓,然後畫在另外一張圖片上,這樣這張新圖片就不再需要重復解壓了。
這種做法是典型的空間換時間的做法。