微信讀書 iOS性能優化
一、發現問題
首先,根據個人的開發經驗,我不得不承認,當應用發展到一定程度後,性能問題就不可能完全避免。以往我們總是希望能尋找一種解決性能問題的一勞永逸的方法,其實是不太現實的。所以我們換個思路,如何盡早的發現性能問題,然後解決問題。
在發現問題方面,我們項目也並沒有什麼高招,主要有兩個方面
-
用戶反饋(包括測試人員)受限於測試時間和用戶反饋的積極性,性能問題往往到了比較嚴重的程度,開發人員才真正發現問題。
- 在線監控在線監控主要有業務性能監控和卡頓監控
業務性能監控,主要在我們認為非常關鍵的操作路徑,例如:

卡頓監控,是用了Bugly的工具,然後通過動態下發開關,用抽樣的方法進行上報
還有一些反饋卡頓的用戶,我們也會通過這個方法來查找問題
二、解決問題
然後,在解決性能問題方法,相信大家都累積了很多經驗。
產生性能問題的原因多種多樣,所以解決的辦法也不盡相同,各種奇技淫巧都有可能派上用場,這裡我大概介紹一下我們項目中用到的一些方面:
1. 優化業務流程
2. 合理的線程分配
3. 預處理和延時加載
4. 緩存
5. 使用正確的API
1. 優化業務流程
性能優化看似高深,真正落到實處才會發現,最大的坑往往都隱藏在於業務不斷累積和頻繁變更之處。優化業務流程就是在滿足需求的同時,提出更加高效優雅的解決方案,從根本上解決問題。從實踐來看,這種方法解決問題是最徹底的,但通常也是難度最大的。
這是我們其中一個業務優化的案例
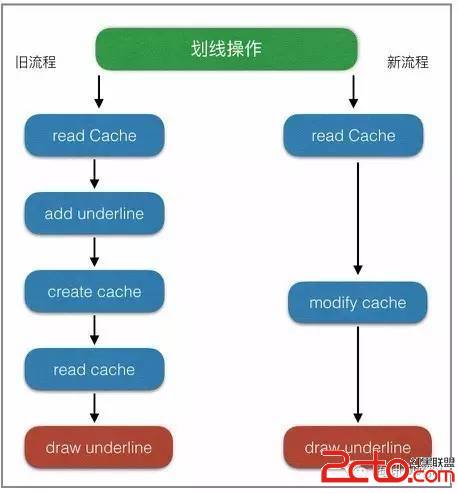
看似挺簡單的優化,但真正落到實處,才會出現其中的坑有多大,所以重構優化的時候,還得有顆堅強的心!
2.合理的線程分配
由於GCD實在太方便了,如果不加控制,大部分需要拋到子線程操作都會被直接加到global隊列,這樣會導致兩個問題:
開的子線程越來越多,線程的開銷逐漸明顯,因為開啟線程需要占用一定的內存空間(默認的情況下,主線程占1M,子線程占用512KB)。多線程情況下,網絡回調的時序問題,導致數據處理錯亂,而且不容易發現。為此,我們項目定了一些基本原則: UI操作和DataSource的操作一定在主線程。DB操作、日志記錄、網絡回調都在各自的固定線程。不同業務,可以通過創建隊列保證數據一致性。例如,想法列表的數據加載、書籍章節下載、書架加載等。
合理的線程分配,最終目的就是保證主線程盡量少的處理非UI操作,同時控制整個App的子線程數量在合理的范圍內。
3.預處理和延時加載。
預處理,是將初次顯示需要耗費大量線程時間的操作,提前放到後台線程進行計算,再將結果數據拿來顯示。
延時加載,是指首先加載當前必須的可視內容,在稍後一段時間內或特定事件時,再觸發其他內容的加載。這種方式可以很有效的提升界面繪制速度,使體驗更加流暢。(UITableView就是最典型的例子)
這兩種方法都是在資源比較緊張的情況下,優先處理馬上要用到的數據,同時盡可能提前加載即將要用到的數據。在微信讀書中閱讀的排版是優先級最高的,所在在閱讀過程中會預處理下一頁、下一章的排版,同時可能會延時加載閱讀相關的其它數據(如想法、劃線、書簽等)。
4.緩存
cache可能是所有性能優化中最常用的手段,但也是我們極不推薦的手段。cache建立的成本低,見效快,但是帶來維護的成本卻很高。如果一定要用,也請謹慎使用,並注意以下幾點:
並發訪問cache時,數據一致性問題。cache線程安全問題,防止一邊修改一邊遍歷的crash。cache查找時性能問題。cache的釋放與重建,避免占用空間無限擴大,同時釋放的粒度也要依實際需求而定。
5.使用正確的API
選擇合適的容器;了解imageNamed與imageWithContentsOfFile的差異(_imageNamed_適用於會重復加載的小圖片,因為系統會自動緩存加載的圖片;_imageWithContentsOfFile_僅加載圖片)緩存NSDateFormatter的結果。尋找__(NSDate *)dateFromString:(NSString )string__的替換品不要隨意使用NSLog();
這方面主要還是靠經驗的累積
上面只是列舉了幾種常規手段,相信大家在實踐過程中,肯定還有很多的高招。
三、預防問題
經過一段時間的性能優化工作,我們團隊達成了一項共識,與其花那麼時間去發現問題,查問題,還不如多開發一些工具,讓問題盡量暴露在開發階段,最好達到避免共性問題。所以,我們總是想開發一些有意思小工具來做這種事情。
下面列舉幾個我們認識還挺有幫忙的工具:
1.內存洩露檢測工具。
2.FPS/SQL性能監測工具條
3.UI/DataSource主線程檢測工具
4.排版引擎自動化檢測工具
5.書源檢測工具
1.內存洩漏檢測工具
1.內存洩漏檢測工具MLeakFinder,這個已經開源了,是我們團隊中zeposhe的傑作。
在此之前,內存洩露引起的性能問題是很難被察覺的,只有洩露到了相當嚴重的程度,然後通過Instrument工具,不斷嘗試才得以定位。MLeakFinder能在開發階段,把內存洩露問題暴露無遺,減少了很多潛在的性能問題。
2.FPS/SQL性能監測工具條。
2.FPS/SQL性能監測工具條。工具條是在DEBUG模式下,以浮窗的形式,實時展示當前可能存在問題的FPS次數和執行時間較長的SQL語句個數,是團隊成員tower開發的。
FPS監測的原理並不復雜,雖然不是百分百准確,但非常實用,因為可以隨時查看FPS低於某個阈值時的堆棧信息,再結合當時的使用場景,開發人員使用起來非常便利,可以很快定位到引起卡頓的場景和原因。SQL語句的監測也非常實用,對於微信讀書,DB的讀寫速度是影響性能的瓶頸之一。因此在DEBUG階段,我們監測了每一條SQL語句的執行速度,一旦執行時間超出某個阈值,就會表現在工具條的數字上,點擊後可以進一步查詢到具體的SQL操作以及實際耗時。

頂部工具條點擊後,就可以查到具體是哪條sql語句慢
這個工具幫助我們在開發階段發現了很多卡頓問題,尤其是一些不合理的SQL語句,例如:在想法圏的優化過程中,利用這個工具,我們就發現想法圈第一次加載更多,執行的SQL語句耗時竟然達到了1000多毫秒。
_SELECT * FROM WRReview INNER JOIN WRUser ON WRReview.fromId = WRUser.vid WHERE WRReview.type & ? AND WRReview.createTime <= ? ORDER BY WRReview.createTime DESC , WRReview.itemId ASC LIMIT ?_
通過explain,可以發現這條SQL效率之低:
SEARCH TABLE WRReview
SEARCH TABLE WRUser USING INTEGER PRIMARY KEY (rowid=?)
USE TEMP B-TREE FOR ORDER BY
沒有建立合適的索引,導致WRReview全表掃描。排序字段沒有索引,導致SQLite需要再一次B-TREE排序。兩字段排序,性能更低。
優化:給WRReview的 fromId createTime 兩個字段增加了索引,並去掉一個排序字段:
_SELECT * FROM WRReview INNER JOIN WRUser ON WRReview.fromId = WRUser.vid WHERE WRReview.type & ? ORDER BY WRReview.createTime DESC LIMIT ?_
Explain的結果:
SCAN TABLE WRReview USING INDEX WRReview_createTime
SEARCH TABLE WRUser USING INTEGER PRIMARY KEY (rowid=?)
SQL執行時間直接降了一個數量級,到100毫秒左右。
3.UI/DataSource主線程檢測工具。
3.UI/DataSource主線程檢測工具。該工具是為了保證所有的UI的操作和DataSource操作一定是在主線程進行。實現原理是通過hook UIView的setNeedsLayout,setNeedsDisplay,setNeedsDisplayInRect三個方法,確保它們都是在主線程執行。子線程操作UI可能會引起什麼問題,蘋果說得並不清楚,實際開發中我們遇到幾種神奇的問題似乎都是跟這個有關。
-
app突然丟動畫,似乎iOS系統也有這個bug。雖然沒有確切的證據,但使用這個工具,改完所有的問題後,bug也好了(不止一次是這樣)。 -
UI操作偶爾響應特別慢,從代碼看沒有任何耗時操作,只是簡單的push某個controller。 莫名的crash,這當然是因為UI操作非線程安全引起的。
更多時候,子線程操作UI也並不一定會發生什麼問題,也正因為不知道會發生什麼,所以更需要我們警惕,這個工具替我們掃除了這些隱患。雖然,蘋果表示,現在部分的UI操作也已經是線程安全了,但畢竟大部分還不是。DataSource的監測是因為我們業務定下的原則,保證列表DataSource的線程安全。
4.排版引擎自動化檢測工具
4.排版引擎自動化檢測工具排版引擎是微信讀書最核心的功能,排版引擎檢測工具原本是為了檢驗排版引擎改進過程中准確性,防止因為業務變更,而影響原來的排版特性。實現原理是結合自動化腳本和App本身的排版引擎,給書庫中的每一本書建立一個鏡像,鏡像的內容包括書籍的每一章每一頁的截圖。然後分析同一頁碼的兩個不同版本的圖片差異,就可以知道不同版本的排版引擎渲染效果。但是我發現,只要稍加改進,排版後記錄每個章節排版耗時,就可以知道每個版本變化後同一個章節的耗時變化,以此作為排版引擎的性能指標。這個工具保證了微信讀書,即使在快速迭代過程中也不會丟失閱讀的核心體驗。雖然這個工具無法在其它項目中復用,但是提醒了我們,可以通過自動化工具來保證產品最核心功能的體驗。
這個雖然業務相關性比較強,但是對於某些應用的自動化測試也是有效的
5.書源檢測工具
5.書源檢測工具微信讀書為了支持正版版權,目前書源完全依賴於後台,不允許本地導入。書源的優劣的直接影響排版的效果和性能。為了解決了部分書籍無法打開或者亂碼的問題,我們借助了後台同學的書源檢測工具。對線上所有epub書籍(大概13,000本)進行掃描,按照章節大小進行排序。對於章節內容特別大的書籍重點檢測,重新排版,解決了一批epub書籍無法打開的問題。同時針對章節內容亂碼的問題,對所有txt的書籍進行了一次全量掃描,發現了一些問題,但還無法准確找出所有亂碼的章節,這一點還在努力改善中。
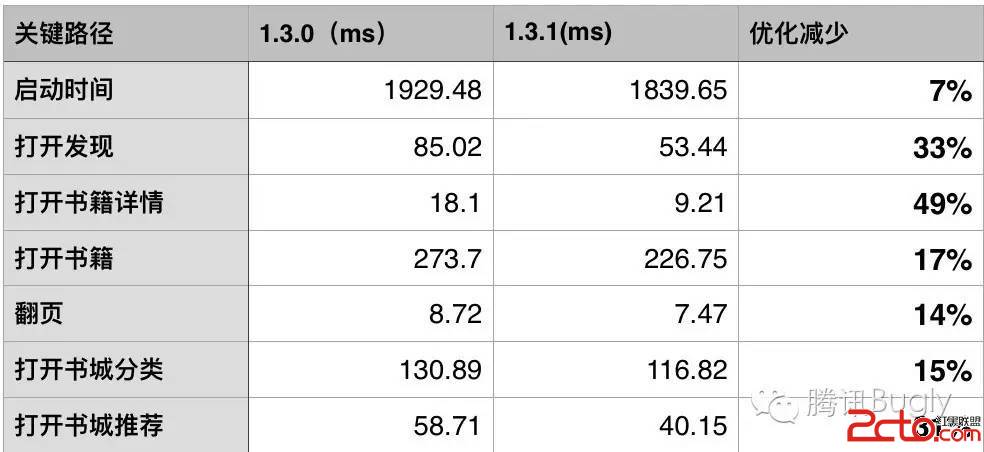
四、優化成果
四、優化成果整體使用感受上,已經可以明顯區分兩個版本的性能差異,這一點也可以通過每天的用戶反饋數據中得到驗證。1.3.0和1.3.1分別發布一周後反饋的卡頓數從10個降到了3個,從總體反饋比例的2.8%降到0.8%。某些關鍵業務,耗時也有明顯改善。極端案例的修復。超大的epub書籍已通過後台進行拆分,解決了無法打開書籍的情況。針對低端機型,去掉了某些動畫,交互更加流暢。
五、總結
五、總結通過上述介紹,我們可以看出,性能問題普遍存在,無可避免,與其花費大量時間,查找線上版本的性能問題,不如提高整體團隊成員性能優化意識,借助性能查找工具,將性能問題盡早暴露在開發階段,達到預防為主的效果。