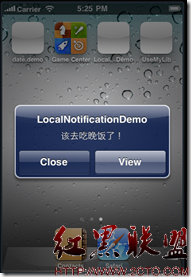
ios 一個正則表達式測試(只可輸入中文、字母和數字)
匹配9-15個由字母/數字組成的字符串的正則表達式:
NSString * regex = @"^[A-Za-z0-9]{9,15}$";
NSPredicate *pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
BOOL isMatch = [pred evaluateWithObject:txtfldPhoneNumber.text];
假如是在OC裡用,一定要注意細節。
列出我在項目中用到的代碼:

NSString *regex = @"[a-zA-Z\u4e00-\u9fa5][a-zA-Z0-9\u4e00-\u9fa5]+";
NSPredicate *pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
if(![pred evaluateWithObject: nickNameTextField.text])
{
/*
////此動畫為彈出buttonqww
UIAlertView *alertView = [[UIAlertView alloc]initWithTitle:@"提示" message:@"昵稱只能由中文、字母或數字組成" delegate:self cancelButtonTitle:@"確定" otherButtonTitles: nil];
[alertView show];
return;
*/
Warning_boxes *reminderView = [[Warning_boxes alloc]init];
[self.view addSubview:reminderView];
reminderView.title_alter.text = @"昵稱只能由中文、字母或數字組成";
[reminderView animationStart];
[reminderView release];
/*
//此動畫為在頂上顯示文字
[MPNotificationView notifyWithText:@"昵稱只能由中文、字母或數字組成"
andDuration:0.5];
*/
return;

下一行代碼非常關鍵:
if(![pred evaluateWithObject: nickNameTextField.text])
這裡有 ! 一定要注意。因為nickNameTextField.text和pred匹配的時候返回的是YES。所以在判斷他們匹配時的情況要加 ! 。
說 明:正則表達式通常用於兩種任務:1.驗證,2.搜索/替換。用於驗證時,通常需要在前後分別加上^和$,以匹配整個待驗證字符串;搜索/替換時是否加上 此限定則根據搜索的要求而定,此外,也有可能要在前後加上\b而不是^和$。此表所列的常用正則表達式,除個別外均未在前後加上任何限定,請根據需要,自 行處理。
正則表達式 :是指一個用來描述或者匹配一系列符合某個句法規則的字符串的單個字符串,簡單說,就是我們寫個模板,然後去匹配字符串。
下面我們來看看一些基本的正則表達式的語法:
\:將下個字符標記為一個特殊的字符、一個原義字符、一個向後引用或者一個八進制轉義符例如“\n”就是匹配一個換行符。
^:匹配開始位置,^(a)這個就匹配開頭必須為a。
$:匹配結束位置,$(a)這個就匹配結尾必須為a。
*:匹配前面的子表達式零次或者多次,如“xu*”這個表達式就能夠匹配“x”和“xuu”。
+:匹配前面的子表達式一次或者多次,如“xu+”這個表達式就能夠匹配“xuu”和“xu”,但不能夠匹配“x”,這個就是和“*”的區別。
?:匹配前面的子表達式零次或者一次,如“xu?”這個表達式就能夠匹配“jian(guo)?”就可以匹配“jian”和“jianguo”。
{n}:n是一個非負數,匹配n次,如“guo{2}”,可以匹配“guoo”,不能匹配“guo”。
{n,}:n是一個非負數,匹配至少n次。
{n, m}:m、n都是非負數,最少匹配n次,最多匹配m次。
(pattern):匹配pattern並獲取匹配結果。
(?:pattern):匹配pattern但不獲取匹配結果。
x|y:匹配x或y,如“(xu|jian)guo”匹配“xuguo”或者“jianguo”。
[xyz]:字符集合,匹配所包含的任意字符。如“[abc]”可以匹配“apple”中的“a”。
[^xyz]:匹配未被包含的字符。
[a-z]:字符范圍,匹配指定范圍內的任意字符。
[^a-z]:匹配指定不在范圍內的任意字符。
\b:匹配一個單詞的邊界,如“guo\b”可以匹配“xujianguo”中的“guo”。
\B:匹配非單詞邊界,如“jian\B”可以匹配“xujianguo”中的“jian”。
\d:匹配一個數字字符,等價於“[0-9]”。
\D:匹配一個非數字字符。
\f:匹配一個換頁符。
\n:匹配一個換行符。
\r:匹配一個回車符。
\s:匹配任何空白字符
其實還有很多語法我就不一一列舉了,先說這麼多先
一.NSString自帶的正則查找,替換方法
正則查找方法
– rangeOfString:options:
– rangeOfString:options:range:
– rangeOfString:options:range:locale:
正則替換方法
– stringByReplacingOccurrencesOfString:withString:options:range:
options參數指定搜索選項,類型為 NSStringCompareOptions ,可通過位或操作指定為 NSCaseInsensitiveSearch , NSLiteralSearch , NSBackwardsSearch , NSAnchoredSearch >等選項的組合。
若指定的選項為 NSRegularExpressionSearch ,則搜索字符串被認為是ICU兼容的正則表達式,如果指定了此選項,則與其可以同時存在的選項只有NSCaseInsensitiveSearch 和 NSAnchoredSearch
二.使用 RegexKitLite
RegexKitLite向標准NSString類增加了很多方法來使用正則表達式,RegexKitLite使用iOS系統自帶的ICU( International Components for Unicode )正則引擎處理正則表達式,所以RegexKitLite使用的正則語法為ICU的語法,使用RegexKitLite需要導入libicucore.dylib庫。
使用RegexKitLite的方法很簡單,將RegexKitLite.h和RegexKitLite.m加入到工程,然後引入libicucore.dylib庫即可。
RegexKitLite.h RegexKitLite.m
RegexKitLit NSString方法參考
RegexKitLite NSString Additions Reference
RegexKitLite的使用說明見:
Using RegexKitLite
ICU正則語法為:
ICU Syntax
ICU User Guide – Regular Expressions
三.使用 RegexKit.framework 框架
RegexKit Framework與RegexKitLite來自同一體系,但其更復雜和強大。RegexKit Framework不使用iOS系統的ICU正則庫,而是自帶 PCRE( Perl Compatible Regular Expressions )庫, 所以其正則語法是PCRE的語法。
RegexKit Framework功能很強大,其向NSArray,NSData,NSDictionary,NSSet和NSString對象增加了正則表達式的支持。
TRegexKit.framework與 RegexKit Lite 的區別
四.常用ICU正則匹配模式
常用的ICU正則匹配模式見:
RegexKitLite Cookbook
文本文件 Text Files
網絡與URL相關 Network and URL
五.貪婪匹配與最小匹配
在正則表達式中單獨使用*或+時,默認是匹配盡可能多的數據,即貪婪匹配。
* Match zero or more times. Match as many times as possible. + Match one or more times. Match as many times as possible.
比如對 abcdefgabcdefg 使用abc(.*)g進行匹配,則捕獲到到的數據為 defgabcdef。
若只想捕獲到第一個g,即只想得到def,則需要使用最小匹配,在*或+後面加上?,即使用abc(.*?)g進行匹配。
*? Match zero or more times. Match as few times as possible. +? Match one or more times. Match as few times as possible.
另外,在正則中用(…)包含內容是要捕獲的數據,如果只要用(…)來引用group而不想捕獲則可使用(?:…)。
(…) Capturing parentheses. Range of input that matched the parenthesized subexpression is available after the match. (?:…) Non-capturing parentheses. Groups the included pattern, but does not provide capturing of matching text. Somewhat more efficient than capturing parentheses.
六.正則表達式書寫格式
在書寫正則表達式時,需要將\進行轉義,即寫成兩個\\。
例如 匹配IP地址的正則表達式為 \b(?:\d{1,3}\.){3}\d{1,3}\b,則在實際書寫時則為
NSString *regex = @"\\b(?:\\d{1,3}\.){3}\\d{1,3}\\b";
常用的第三方正則庫:
匹配中文字符的正則表達式: [\u4e00-\u9fa5]
評注:匹配中文還真是個頭疼的事,有了這個表達式就好辦了
匹配雙字節字符(包括漢字在內):[^\x00-\xff]
評注:可以用來計算字符串的長度(一個雙字節字符長度計2,ASCII字符計1)
匹配空白行的正則表達式:\n\s*\r
評注:可以用來刪除空白行
匹配HTML標記的正則表達式:<(\S*?)[^>]*>.*?|<.*? />
評注:網上流傳的版本太糟糕,上面這個也僅僅能匹配部分,對於復雜的嵌套標記依舊無能為力
匹配首尾空白字符的正則表達式:^\s*|\s*$
評注:可以用來刪除行首行尾的空白字符(包括空格、制表符、換頁符等等),非常有用的表達式
匹配Email地址的正則表達式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
評注:表單驗證時很實用
匹配網址URL的正則表達式:[a-zA-z]+://[^\s]*
評注:網上流傳的版本功能很有限,上面這個基本可以滿足需求
匹配帳號是否合法(字母開頭,允許5-16字節,允許字母數字下劃線):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
評注:表單驗證時很實用
匹配國內電話號碼:\d{3}-\d{8}|\d{4}-\d{7}
評注:匹配形式如 0511-4405222 或 021-87888822
匹配騰訊QQ號:[1-9][0-9]{4,}
評注:騰訊QQ號從10000開始
匹配中國郵政編碼:[1-9]\d{5}(?!\d)
評注:中國郵政編碼為6位數字
匹配身份證:\d{15}|\d{18}
評注:中國的身份證為15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
評注:提取ip地址時有用
匹配特定數字:
^[1-9]\d*$ //匹配正整數
^-[1-9]\d*$ //匹配負整數
^-?[1-9]\d*$ //匹配整數
^[1-9]\d*|0$ //匹配非負整數(正整數 + 0)
^-[1-9]\d*|0$ //匹配非正整數(負整數 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮點數
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配負浮點數
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮點數
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非負浮點數(正浮點數 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮點數(負浮點數 + 0)
評注:處理大量數據時有用,具體應用時注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26個英文字母組成的字符串
^[A-Z]+$ //匹配由26個英文字母的大寫組成的字符串
^[a-z]+$ //匹配由26個英文字母的小寫組成的字符串
^[A-Za-z0-9]+$ //匹配由數字和26個英文字母組成的字符串
^\w+$ //匹配由數字、26個英文字母或者下劃線組成的字符串
< input onkeypress="return /[\w\u4e00-\u9fa5]/.test(String.fromCharCode(window.event.keyCode))"
onpaste="return !/[^\w\u4e00-\u9fa5]/g.test(window.clipboardData.getData('Text'))"
ondragenter="return false"/>
再粘貼一些別人寫的。
1.只能輸入數字和英文的:
2.只能輸入數字的:
3.只能輸入全角的:
4.只能輸入漢字的:
5.郵件地址驗證:
var regu = "^(([0-9a-zA-Z]+)|([0-9a-zA-Z]+[_.0-9a-zA-Z-]*[0-9a-zA-Z]+))@([a-zA-Z0-9-]+[.])+([a-zA-Z]{2}|net|NET|com|COM|gov|GOV|mil|MIL|org|ORG|edu|EDU|int|INT)$"
var re = new RegExp(regu);
if (s.search(re) != -1) {
return true;
} else {
window.alert ("請輸入有效合法的E-mail地址 !")
return false;
}
6.身份證:
"^\\d{17}(\\d|x)$"
7.17種正則表達式
"^\\d+$" //非負整數(正整數 + 0)
"^[0-9]*[1-9][0-9]*$" //正整數
"^((-\\d+)|(0+))$" //非正整數(負整數 + 0)
"^-[0-9]*[1-9][0-9]*$" //負整數
"^-?\\d+$" //整數
"^\\d+(\\.\\d+)?$" //非負浮點數(正浮點數 + 0)
"^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮點數
"^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$" //非正浮點數(負浮點數 + 0)
"^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //負浮點數
"^(-?\\d+)(\\.\\d+)?$" //浮點數
"^[A-Za-z]+$" //由26個英文字母組成的字符串
"^[A-Z]+$" //由26個英文字母的大寫組成的字符串
"^[a-z]+$" //由26個英文字母的小寫組成的字符串
"^[A-Za-z0-9]+$" //由數字和26個英文字母組成的字符串
"^\\w+$" //由數字、26個英文字母或者下劃線組成的字符串
"^[\\w-]+(\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$" //email地址
"^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$" //url
=============================================
1.取消按鈕按下時的虛線框
在input裡添加屬性值 hideFocus 或者 HideFocus=true
2.只讀文本框內容
在input裡添加屬性值 readonly
3.防止退後清空的TEXT文檔(可把style內容做做為類引用)
4.ENTER鍵可以讓光標移到下一個輸入框
5.只能為中文(有閃動)
6.只能為數字(有閃動)
7.只能為數字(無閃動)
8.只能輸入英文和數字(有閃動)
9.屏蔽輸入法
10. 只能輸入 數字,小數點,減號(-) 字符(無閃動)
11. 只能輸入兩位小數,三位小數(有閃動)
javascript正則表達式使用詳解
簡介簡單的說,正則表達式是一種可以用於模式匹配和替換的強有力的工具。其作用如下:
測試字符串的某個模式。例如,可以對一個輸入字符串進行測試,看在該字符串是否存在一個電話號碼模式或一個信用卡號碼模式。這稱為數據有效性驗證。
替換文本。可以在文檔中使用一個正則表達式來標識特定文字,然後可以全部將其刪除,或者替換為別的文字。
根據模式匹配從字符串中提取一個子字符串。可以用來在文本或輸入字段中查找特定文字。
基本語法
在對正則表達式的功能和作用有了初步的了解之後,我們就來具體看一下正則表達式的語法格式。
正則表達式的形式一般如下:
/love/ 其中位於“/”定界符之間的部分就是將要在目標對象中進行匹配的模式。用戶只要把希望查找匹配對象的模式內容放入“/”定界符之間 即可。為了能夠使用戶更加靈活的定制模式內容,正則表達式提供了專門的“元字符”。所謂元字符就是指那些在正則表達式中具有特殊意義的專用字符,可以用來 規定其前導字符(即位於元字符前面的字符)在目標對象中的出現模式。
較為常用的元字符包括: “+”, “*”,以及 “?”。
“+”元字符規定其前導字符必須在目標對象中連續出現一次或多次。
“*”元字符規定其前導字符必須在目標對象中出現零次或連續多次。
“?”元字符規定其前導對象必須在目標對象中連續出現零次或一次。
下面,就讓我們來看一下正則表達式元字符的具體應用。
/fo+/ 因為上述正則表達式中包含“+”元字符,表示可以與目標對象中的 “fool”, “fo”, 或者 “football”等在字母f後面連續出現一個或多個字母o的字符串相匹配。
/eg*/ 因為上述正則表達式中包含“*”元字符,表示可以與目標對象中的 “easy”, “ego”, 或者 “egg”等在字母e後面連續出現零個或多個字母g的字符串相匹配。
/Wil?/ 因為上述正則表達式中包含“?”元字符,表示可以與目標對象中的 “Win”, 或者“Wilson”,等在字母i後面連續出現零個或一個字母l的字符串相匹配。
有時候不知道要匹配多少字符。為了能適應這種不確定性,正則表達式支持限定符的概念。這些限定符可以指定正則表達式的一個給定組件必須要出現多少次才能滿足匹配。
{n} n 是一個非負整數。匹配確定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的兩個 o。
{n,} n 是一個非負整數。至少匹配 n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等價於 'o+'。'o{0,}' 則等價於 'o*'。
{n,m} m 和 n 均為非負整數,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 將匹配 "fooooood" 中的前三個 o。'o{0,1}' 等價於 'o?'。請注意在逗號和兩個數之間不能有空格。
除了元字符之外,用戶還可以精確指定模式在匹配對象中出現的頻率。例如,/jim {2,6}/ 上述正則表達式規定字符m可以在匹配對象中連續出現2-6次,因此,上述正則表達式可以同jimmy或jimmmmmy等字符串相匹配。
在對如何使用正則表達式有了初步了解之後,我們來看一下其它幾個重要的元字符的使用方式。
- \s:用於匹配單個空格符,包括tab鍵和換行符;
- \S:用於匹配除單個空格符之外的所有字符;
- \d:用於匹配從 0 到 9 的數字;
- \w:用於匹配字母,數字或下劃線字符;
- \W:用於匹配所有與\w不匹配的字符;
- . :用於匹配除換行符之外的所有字符。
下面,我們就通過實例看一下如何在正則表達式中使用上述元字符。
/\s+/ 上述正則表達式可以用於匹配目標對象中的一個或多個空格字符。
/\d000/ 如果我們手中有一份復雜的財務報表,那麼我們可以通過上述正則表達式輕而易舉的查找到所有總額達千元的款項。
除了我們以上所介紹的元字符之外,正則表達式中還具有另外一種較為獨特的專用字符,即定位符。定位符用於規定匹配模式在目標對象中的出現位置。 較為常用的定位符包括: “^”, “$”, “\b” 以及 “\B”。 代碼
- “^”定位符規定匹配模式必須出現在目標字符串的開頭
- “$”定位符規定匹配模式必須出現在目標對象的結尾
- “\b”定位符規定匹配模式必須出現在目標字符串的開頭或結尾的兩個邊界之一
- “\B”定位符則規定匹配對象必須位於目標字符串的開頭和結尾兩個邊界之內,
- 即匹配對象既不能作為目標字符串的開頭,也不能作為目標字符串的結尾。
為了能夠方便用戶更加靈活的設定匹配模式,正則表達式允許使用者在匹配模式中指定某一個范圍而不局限於具體的字符。例如: 代碼
- /[A-Z]/ 上述正則表達式將會與從A到Z范圍內任何一個大寫字母相匹配。
- /[a-z]/ 上述正則表達式將會與從a到z范圍內任何一個小寫字母相匹配。
- /[ 0 - 9 ]/ 上述正則表達式將會與從 0 到 9 范圍內任何一個數字相匹配。
- /([a-z][A-Z][ 0 - 9 ])+/ 上述正則表達式將會與任何由字母和數字組成的字符串,如 “aB0” 等相匹配。
如果我們希望在正則表達式中實現類似編程邏輯中的“或”運算,在多個不同的模式中任選一個進行匹配的話,可以使用管道符 “|”。例如:/to|too|2/ 上述正則表達式將會與目標對象中的 “to”, “too”, 或 “2” 相匹配。
正則表達式中還有一個較為常用的運算符,即否定符 “[^]”。與我們前文所介紹的定位符 “^” 不同,否定符 “[^]”規定目標對象中不能存在模式中所規定的字符串。例如:/[^A-C]/ 上述字符串將會與目標對象中除A,B,和C之外的任何字符相匹配。一般 來說,當“^”出現在 “[]”內時就被視做否定運算符;而當“^”位於“[]”之外,或沒有“[]”時,則應當被視做定位符。
最後,當用戶需要在正則表達式的模式中加入元字符,並查找其匹配對象時,可以使用轉義符“\”。例如:/Th\*/ 上述正則表達式將會與目標對象中的“Th*”而非“The”等相匹配。
在構造正則表達式之後,就可以象數學表達式一樣來求值,也就是說,可以從左至右並按照一個優先級順序來求值。優先級如下: 代碼
- 1 .\ 轉義符
- 2 .(), (?:), (?=), [] 圓括號和方括號
- 3 .*, +, ?, {n}, {n,}, {n,m} 限定符
- 4 .^, $, \anymetacharacter 位置和順序
- 5 .|“或”操作
使用實例
在JavaScript 1.2中帶有一個功能強大的RegExp()對象,可以用來進行正則表達式的匹配操作。其中的test()方法可以檢驗目標對象中是否包含匹配模式,並相應的返回true或false。
我們可以使用JavaScript編寫以下腳本,驗證用戶輸入的郵件地址的有效性。
- < html >
- < head >
- < script language = "Javascript1.2" >