iOS10語音識別框架SpeechFramework應用詳解
摘要: iOS10語音識別框架SpeechFramework應用
一、引言
iOS10系統是一個較有突破性的系統,其在Message,Notification等方面都開放了很多實用性的開發接口。本篇博客將主要探討iOS10中新引入的SpeechFramework框架。有個這個框架,開發者可以十分容易的為自己的App添加語音識別功能,不需要再依賴於其他第三方的語音識別服務,並且,Apple的Siri應用的強大也證明了Apple的語音服務是足夠強大的,不通過第三方,也大大增強了用戶的安全性。
二、SpeechFramework框架中的重要類
SpeechFramework框架比較輕量級,其中的類並不十分冗雜,在學習SpeechFramework框架前,我們需要對其中類與類與類之間的關系有個大致的熟悉了解。
SFSpeechRecognizer:這個類是語音識別的操作類,用於語音識別用戶權限的申請,語言環境的設置,語音模式的設置以及向Apple服務發送語音識別的請求。
SFSpeechRecognitionTask:這個類是語音識別服務請求任務類,每一個語音識別請求都可以抽象為一個SFSpeechRecognitionTask實例,其中SFSpeechRecognitionTaskDelegate協議中約定了許多請求任務過程中的監聽方法。
SFSpeechRecognitionRequest:語音識別請求類,需要通過其子類來進行實例化。
SFSpeechURLRecognitionRequest:通過音頻URL來創建語音識別請求。
SFSpeechAudioBufferRecognitionRequest:通過音頻流來創建語音識別請求。
SFSpeechRecognitionResult:語音識別請求結果類。
SFTranscription:語音轉換後的信息類。
SFTranscriptionSegment:語音轉換中的音頻節點類。
了解了上述類的作用於其之間的聯系,使用SpeechFramework框架將十分容易。
三、申請用戶語音識別權限與進行語音識別請求
開發者若要在自己的App中使用語音識別功能,需要獲取用戶的同意。首先需要在工程的Info.plist文件中添加一個Privacy-Speech Recognition Usage Description鍵,其實需要對應一個String類型的值,這個值將會在系統獲取權限的警告框中顯示,Info.plist文件如下圖所示:
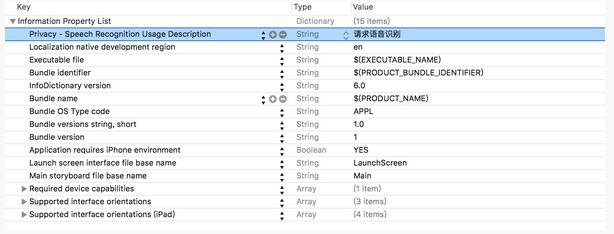
使用SFSpeechRecognize類的requestAuthorization方法來進行用戶權限的申請,用戶的反饋結果會在這個方法的回調block中傳入,如下:
//申請用戶語音識別權限
[SFSpeechRecognizer requestAuthorization:^(SFSpeechRecognizerAuthorizationStatus status) {
}];
SFSpeechRecognizerAuthorzationStatus枚舉中定義了用戶的反饋結果,如下:
typedef NS_ENUM(NSInteger, SFSpeechRecognizerAuthorizationStatus) {
//結果未知 用戶尚未進行選擇
SFSpeechRecognizerAuthorizationStatusNotDetermined,
//用戶拒絕授權語音識別
SFSpeechRecognizerAuthorizationStatusDenied,
//設備不支持語音識別功能
SFSpeechRecognizerAuthorizationStatusRestricted,
//用戶授權語音識別
SFSpeechRecognizerAuthorizationStatusAuthorized,
};
如果申請用戶語音識別權限成功,開發者可以通過SFSpeechRecognizer操作類來進行語音識別請求,示例如下:
//創建語音識別操作類對象
SFSpeechRecognizer * rec = [[SFSpeechRecognizer alloc]init];
//通過一個音頻路徑創建音頻識別請求
SFSpeechRecognitionRequest * request = [[SFSpeechURLRecognitionRequest alloc]initWithURL:[[NSBundle mainBundle] URLForResource:@"7011" withExtension:@"m4a"]];
//進行請求
[rec recognitionTaskWithRequest:request resultHandler:^(SFSpeechRecognitionResult * _Nullable result, NSError * _Nullable error) {
//打印語音識別的結果字符串
NSLog(@"%@",result.bestTranscription.formattedString);
}];
四、深入SFSpeechRecognizer類
SFSpeechRecognizer類的主要作用是申請權限,配置參數與進行語音識別請求。其中比較重要的屬性與方法如下:
//獲取當前用戶權限狀態
+ (SFSpeechRecognizerAuthorizationStatus)authorizationStatus;
//申請語音識別用戶權限
+ (void)requestAuthorization:(void(^)(SFSpeechRecognizerAuthorizationStatus status))handler;
//獲取所支持的所有語言環境
+ (NSSet<NSLocale *> *)supportedLocales;
//初始化方法 需要注意 這個初始化方法將默認以設備當前的語言環境作為語音識別的語言環境
- (nullable instancetype)init;
//初始化方法 設置一個特定的語言環境
- (nullable instancetype)initWithLocale:(NSLocale *)locale NS_DESIGNATED_INITIALIZER;
//語音識別是否可用
@property (nonatomic, readonly, getter=isAvailable) BOOL available;
//語音識別操作類協議代理
@property (nonatomic, weak) id<SFSpeechRecognizerDelegate> delegate;
//設置語音識別的配置參數 需要注意 在每個語音識別請求中也有這樣一個屬性 這裡設置將作為默認值
//如果SFSpeechRecognitionRequest對象中也進行了設置 則會覆蓋這裡的值
/*
typedef NS_ENUM(NSInteger, SFSpeechRecognitionTaskHint) {
SFSpeechRecognitionTaskHintUnspecified = 0, // 無定義
SFSpeechRecognitionTaskHintDictation = 1, // 正常的聽寫風格
SFSpeechRecognitionTaskHintSearch = 2, // 搜索風格
SFSpeechRecognitionTaskHintConfirmation = 3, // 短語風格
};
*/
@property (nonatomic) SFSpeechRecognitionTaskHint defaultTaskHint;
//使用回調Block的方式進行語音識別請求 請求結果會在Block中傳入
- (SFSpeechRecognitionTask *)recognitionTaskWithRequest:(SFSpeechRecognitionRequest *)request
resultHandler:(void (^)(SFSpeechRecognitionResult * __nullable result, NSError * __nullable error))resultHandler;
//使用代理回調的方式進行語音識別請求
- (SFSpeechRecognitionTask *)recognitionTaskWithRequest:(SFSpeechRecognitionRequest *)request
delegate:(id <SFSpeechRecognitionTaskDelegate>)delegate;
//設置請求所占用的任務隊列
@property (nonatomic, strong) NSOperationQueue *queue;
SFSpeechRecognizerDelegate協議中只約定了一個方法,如下:
//當語音識別操作可用性發生改變時會被調用 - (void)speechRecognizer:(SFSpeechRecognizer *)speechRecognizer availabilityDidChange:(BOOL)available;
通過Block回調的方式進行語音識別請求十分簡單,如果使用代理回調的方式,開發者需要實現SFSpeechRecognitionTaskDelegate協議中的相關方法,如下:
//當開始檢測音頻源中的語音時首先調用此方法 - (void)speechRecognitionDidDetectSpeech:(SFSpeechRecognitionTask *)task; //當識別出一條可用的信息後 會調用 /* 需要注意,apple的語音識別服務會根據提供的音頻源識別出多個可能的結果 每有一條結果可用 都會調用此方法 */ - (void)speechRecognitionTask:(SFSpeechRecognitionTask *)task didHypothesizeTranscription:(SFTranscription *)transcription; //當識別完成所有可用的結果後調用 - (void)speechRecognitionTask:(SFSpeechRecognitionTask *)task didFinishRecognition:(SFSpeechRecognitionResult *)recognitionResult; //當不再接受音頻輸入時調用 即開始處理語音識別任務時調用 - (void)speechRecognitionTaskFinishedReadingAudio:(SFSpeechRecognitionTask *)task; //當語音識別任務被取消時調用 - (void)speechRecognitionTaskWasCancelled:(SFSpeechRecognitionTask *)task; //語音識別任務完成時被調用 - (void)speechRecognitionTask:(SFSpeechRecognitionTask *)task didFinishSuccessfully:(BOOL)successfully;
SFSpeechRecognitionTask類中封裝了屬性和方法如下:
//此任務的當前狀態
/*
typedef NS_ENUM(NSInteger, SFSpeechRecognitionTaskState) {
SFSpeechRecognitionTaskStateStarting = 0, // 任務開始
SFSpeechRecognitionTaskStateRunning = 1, // 任務正在運行
SFSpeechRecognitionTaskStateFinishing = 2, // 不在進行音頻讀入 即將返回識別結果
SFSpeechRecognitionTaskStateCanceling = 3, // 任務取消
SFSpeechRecognitionTaskStateCompleted = 4, // 所有結果返回完成
};
*/
@property (nonatomic, readonly) SFSpeechRecognitionTaskState state;
//音頻輸入是否完成
@property (nonatomic, readonly, getter=isFinishing) BOOL finishing;
//手動完成音頻輸入 不再接收音頻
- (void)finish;
//任務是否被取消
@property (nonatomic, readonly, getter=isCancelled) BOOL cancelled;
//手動取消任務
- (void)cancel;
關於音頻識別請求類,除了可以使用SFSpeechURLRecognitionRequest類來進行創建外,還可以使用SFSpeechAudioBufferRecognitionRequest類來進行創建:
@interface SFSpeechAudioBufferRecognitionRequest : SFSpeechRecognitionRequest @property (nonatomic, readonly) AVAudioFormat *nativeAudioFormat; //拼接音頻流 - (void)appendAudioPCMBuffer:(AVAudioPCMBuffer *)audioPCMBuffer; - (void)appendAudioSampleBuffer:(CMSampleBufferRef)sampleBuffer; //完成輸入 - (void)endAudio; @end
五、語音識別結果類SFSpeechRecognitionResult
SFSpeechRecognitionResult類是語音識別結果的封裝,其中包含了許多套平行的識別信息,其每一份識別信息都有可信度屬性來描述其准確程度。SFSpeechRecognitionResult類中屬性如下:
//識別到的多套語音轉換信息數組 其會按照准確度進行排序 @property (nonatomic, readonly, copy) NSArray<SFTranscription *> *transcriptions; //准確性最高的識別實例 @property (nonatomic, readonly, copy) SFTranscription *bestTranscription; //是否已經完成 如果YES 則所有所有識別信息都已經獲取完成 @property (nonatomic, readonly, getter=isFinal) BOOL final;
SFSpeechRecognitionResult類只是語音識別結果的一個封裝,真正的識別信息定義在SFTranscription類中,SFTranscription類中屬性如下:
//完整的語音識別准換後的文本信息字符串 @property (nonatomic, readonly, copy) NSString *formattedString; //語音識別節點數組 @property (nonatomic, readonly, copy) NSArray<SFTranscriptionSegment *> *segments;
當對一句完整的話進行識別時,Apple的語音識別服務實際上會把這句語音拆分成若干個音頻節點,每個節點可能為一個單詞,SFTranscription類中的segments屬性就存放這些節點。SFTranscriptionSegment類中定義的屬性如下:
//當前節點識別後的文本信息 @property (nonatomic, readonly, copy) NSString *substring; //當前節點識別後的文本信息在整體識別語句中的位置 @property (nonatomic, readonly) NSRange substringRange; //當前節點的音頻時間戳 @property (nonatomic, readonly) NSTimeInterval timestamp; //當前節點音頻的持續時間 @property (nonatomic, readonly) NSTimeInterval duration; //可信度/准確度 0-1之間 @property (nonatomic, readonly) float confidence; //關於此節點的其他可能的識別結果 @property (nonatomic, readonly) NSArray<NSString *> *alternativeSubstrings;
溫馨提示:SpeechFramework框架在模擬器上運行會出現異常情況,無法進行語音識別請求。會報出kAFAssistantErrorDomain的錯誤,還望有知道解決方案的朋友,給些建議,Thanks。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持本站。
- 上一頁:輕松搞定iOS本地消息推送
- 下一頁:iOS 10 推送高階篇(必看)